September 24 2014 Meeting Notes

September 25 2014 Meeting Notes
Brian Terlson (BT), Allen Wirfs-Brock (AWB), John Neumann (JN), Rick Waldron (RW), Eric Ferraiuolo (EF), Jeff Morrison (JM), Jonathan Turner (JT), Sebastian Markbage (SM), Istvan Sebestyen (phone) (IS), Erik Arvidsson (EA), Brendan Eich (BE), Domenic Denicola (DD), Peter Jensen (PJ), Eric Toth (ET), Yehuda Katz (YK), Dave Herman (DH), Brendan Eich (BE), Simon Kaegi (SK), Boris Zbarsky (BZ), Andreas Rossberg (ARB), Caridy Patino (CP), Niko Matsakis (NM), Mark Miller (MM), Matt Miller (MMR), Jaswanth Sreeram (JS)
5.8 Object Rest Destructuring and Spread Properties
(Sebastian Markbage)
Spec sebmarkbage/ecmascript-rest-spread
Request Slides
SM: Update: own properties?
- Need to be own properties
Object.prototype.hostile = 1;
let { ...o } = {};
let o = { ...{} };
o.hostile; // 1
o.hasOwnProperty("hostile"); // true
MM: clarifies hostile vs. accidental
MM: When does Object.assign do toMethod?
RW: Never. That was designed for Object.define/mixin
AWB: Confirm
SM: Mental model:
...o
expands keys = Object.keys(o) to
o[keys[0]], o[keys[1]], o[keys[2]]
Security Consideration?
Syntax introduces a new way to determine "ownness" without going through (patchable) library functions:
- Object.prototype.hasOwnProperty
- Object.keys
MM: Explains that SES is capable of patching the above by replacing these APIs. Rewriting syntax is undesirable.
Discussion about ownness and enumerability
YK:
MM: If we proceed assuming weak maps are not slow, then they won't be (i.e., browsers will finally switch to the transposed representation)
YK: As a lib impl, weak maps are slow and I have no reason to believe they'll be fast in the near future, so I won't use them
AWB: Not our job to design lang around what things are slow today
ARB: concerned about proliferating the use of enumerability
AWB: Had this discussion many times. Enumerable is obselete reflection of semantics of for-in. Don't want people to use enumerable to start meaning new things.
YK: We agreed it's obselete function of for-in, but it is widely used. So can't change the way it's assumed to work
AWB: Today, in es5, enumerability used as a way to deal with copying
MM: WRT proposal on table, it is a copying API. So you're agreeing with the fact that the proposal on table is sensitive to enumerability
YK: Yes
ARB: This is only really useful for record copying
AWB: Let's talk about own again. This is an extension of obj destructuring -- which, as it exists today, does not restrict prop accesses to own properties.
AWB: However, it does restrict/ignores enumerability
AWB: Implication of this being own: You couldn't use a tree structure to represent a set of values:
BaseOpts = {__proto__: null, o1: 1, o2: 2, o3: 3, ... oN: n};
ThisTime = {__proto__: BaseOpts, o7: 14};
foo(ThisTime);
AWB: Now, inside of Foo...
AWB: Since you're excluding non-enumerables, normally things in Object.prototype are excluded. So not worried about picking up those things
YK: You're worried about picking up someone's old prototype extensions. It's true people could do that, but in practice people don't
MM: We have several arguments that say own is what's expected
MM: In ES3, assumption is there's all sorts of gunk on Object.prototype because no way to get rid of it. Reason it was restricted to own-ness was because there was a desire to not iterate stuff on Object.prototype
YK: There's a notion of copying today that means "non-enum, own"
AWB: Notions in JS today are diff from notions 5 years ago and 5 years from now
MM: We can't accomodate legacy in this way forever. We're in a history dependent trap, we should make this (enumerable + own)?[verify]
AWB: How does this play with/needed in the context of other extensions? For example, record types vs property bags to represent options. If people use typed objects vs regular, would expectations change for this syntax?
SM: Brings up another proposal: Records (new proposal) in same realm as TypedObjects, but simpler syntactically
AWB: In the past, when focusing in on a microfeature, it makes sense. But when looking at features more broadly those proposals make sense differently. There are enough things that are coming soon that need to be considered here as well
MM: This feature is on the same "future table" as those other things, so they'll be considered together as we move forward.
SM: Record types don't have a concept of prototype chain, so not even a consideration; So this should operate consistently between those and regular objects
SM: (tries to move on to a new slide)
ARB: so ownness is clear, but are we settled on enumerability?
MM: yes
SM: I think it should be settled, and any argument against the enumerability policy here also appllies to Object.assign
YK: Object.assign is meant to be a widely-used mechanism for copying
ARB: I see your point, but am still concerned...
YK: I think the problem is that people don't like enumerability. I don't like enumerability. But enumerability is how you design copying behavior in this language.
AWB: Is this feature valuable enough to make this as syntax rather than something that lives in a library
MM: Need a functional mechanism for updating records
AWB: This seems like a nice feature, but not sure why this should make it in over other features.
YK: Symmetrical with destructuring, so easy to understand.
MM: This seems like a smaller burden on programmer psychology
AWB: Well, it is a burden. Spread and rest used to be an enumerable list of things, and now we have ... mean something else.
MM: There is a cognitive cost, but because of the analogy it's much less than a new feature.
MM: When we previously produced large specifications (through ES6) we used to determine the complexity everything together. Possible that the yearly release will make it more difficult to budget for complexity.
DH: Also makes it harder to say no to a feature that makes sense locally and has gone through the process.
MM: We should allow for something to get rejected even after it has gotten through all the stages.
YK: It's an implicit requirement. Should make it an explicit requirement.
MM: Agree.
DH: Recognize that this feature is fitting in an existing syntactic space and is rounding out a syntax that already exists.
ARB: It's subtly different...
DH: You'll have to learn it
function ComponentChild({ isFoo, ...rest }) {
var type = isFoo ? 'foo' : 'bar';
return ComponentBase({ ... rest, type });
}
AWB: What happens if rest is an array?
MM/SM: It creates the enumerable array properties.
AWB: But we use iterators.
MM: It should be dependent on the syntactic thing containing the .... In an object literal, ... will enumerate properties.
SM: Stage 1?
Conclusion/Resolution
- Stage 1 approval
AWB: Be sure to mark agenda items that want to advance with some kind of notation, this will help to get pre-meeting attention.
(Confirmed by all)
RW: Use the rocketship icon
YK: I feel like the rocketship icon should be for proposals which are ready to launch
DD: If you bikeshed on the rocketship icon I will change it to a bikeshed icon.
RW: :D
Loader pipeline
AWB: Working on module spec. Questions: Loader pipeline. Can we simplify modules for ES spec?
"A.js"
export let g = 5;
import f from "B.js";
f(g);
"B.js"
import g from "A.js";
export function f(z) {
return z * g;
};
AWB: Essential in ES6 that the semantics of above example code is well defined.
- None of it depends on how the loader is parameterized.
- Strictly at the declarative level of the language
BE: So what goes on the ES side?
AWB: Syntax and semantics (static, linking, and runtime) of declarative modules. Linking does have to be there, but it's linking at the declarative level of the lang.
DH: So you have some small number of low-level integration hooks in ES that expose enough for browser implementors design and build loader pipeline themselves?
AWB: They're at the same level as the other host hooks that we have
AWB: The only host hook is the one that says "there's a request for a module name (from referrer), give me the source code"
DH: To clarify: I think what Allen means by "hook" is not user-visible, it's visible to an engine. It's a spec device used to factor out the pipeline. It's not available to user code, just to the internal semantics of the pipeline.
MM: And we can move the pipeline into a separate spec.
EF: "Authoring and runtime"
- Authoring: actual writing of modules
- Runtime: the loader
(Discussion about Loader polyfill)
(Discussion of how the loader spec would be a separate document)
YK: The loader pipeline will be done in a "living spec" (a la HTML5) so that Node and the browser can collaborate on shared needs.
Conclusion/Resolution
Loader pipeline goes into a separate spec: living document that deals with integration
AWB: Retitle? ECMAScript 2015 (6th edition), and so on
Train Schedule
DH: Let's define the schedule
YK: ES2015 is the first train.
Types
(Jonathan Turner)
type_annotations.pdf
JT: Goals
-
Short term
-
Reserve syntax used by TypeScript, Flow, etc. for some form of annotation
-
Venue for collaboration among interested committtee members
-
Long term
-
Consensus on a shared syntax fr many varied type annotation implementations
-
Consensus on
-
Additionally, a shared syntax for interface definition for documening API boundaries (.d.ts files)
Examples & Demo
...
Rationale: Why Type Annotations?
- Toolability
- Closure
- TypeScript
- Flow
- JSDoc
- Performance
- Asm.js
- Hidden classes/runtime inferences
- API specification
- DefinitelyTyped/.d.ts
- WebIDL
- JSDoc
- Runtime checks/Guarantees
- Guards
- Contracts
Rationale: Why Standardize?
copy from slides
JT: Looking for Stage 0 blessing to pursue type annotations a la TypeScript and .d.ts file definitions.
MM: You've presented annotation, what about checking?
JT: Type checking not defined
- mention of python type design
MM: I'm not familiar
JT: TS, Flow have different type checking rules that will hopefully emerge
DD: Draws comparison to divergent promise implementations that were successfully unified
ARB: the result is rather terrible
MM: The fact that .then came together was a miracle and shouldn't be a
practice.
DH: If we want to agree on reserved syntax that currently has no legal JavaScript overlap, that is it fails, not ignored. If such a thing can be agreed on, then different groups can develop around the syntax divergently. Cannot expect to reserve behavior. The rationale slide is far too vague.
- Goal: TS and Flow are taking a risk where TC39 could easily standardize on a syntax that invalidates those project's uses
JM: no attempt to standardize the entire syntax
-
Python: imagine similar approach
-
annotations
-
arbitrary expressions evaluated then attached to the function object
-
language doesn't need to use them in runtime
-
tooling may use them
-
allows both static and runtime tooling
-
(this point was about third party consumption of type information, needs to be filled in)
-
no guarantee that TS or Flow won't continue extending the grammar
YK: If you give type checks anything but an error, you can't create different semantics later
DH/YK/DD: mixed discussion re: history of type design sets constraints
JM: We need to start making these things possible by putting the capability in the language
STH: underestimating the complexity (refers to DH work)
- Types seem to be doing well in their current form (compile to JS)
- what is the problem we're trying to solve here?
- RE: Python, the underspecification is already causing problems w/ competing groups
JM: to move forward we really need a space that's reserved
DD: Wouldn't have proposed this as types, it's closer to parameter types and returns
YK: decorators suffered the same syntactic space arguments.
MM: I'd propose that you enter Stage 0 with TypeScript.
- TS made a choice and proved that this choice has utility.
DH: Don't need TC39
JM: How do we know when it's time to come to TC39? We need TC39 to help with progress
JM: Various projects working toward similar goals: TypeScript, Safe TypeScript, Closure Compiler, IBM has a project, Flow. Ongoing research that should be collaborating and coordinating with TC39
BE: codify annotation grammar, build object that you can reflect on. Not ready to do that.
- Make reserved syntax, we can do that.
MM: It's just a 16.1 restriction on extensions.
BE: ECMAScript allows and always has allowed implementers to make syntax extensions.
YK: Nashorn adds "#" comment
DH: Difference between TS, Flow and Nashorn
RW: (couldn't say outloud) Nashorn changed JS syntax; TS, Flow compile to JS
JT: Just want to reserve/restrict certain basic block of syntax that projects can use
DH: Syntax reservation has value. Attempting to define some minimal semantics is a bad idea.
BE: (copy grammar from whiteboard)
JM: Would like to be able to point to document for this
AWB: Some kind of "statement of future direction" document
RW: Similar to Future Reserved Word, it's a "Future Reserved Grammar/Syntax"
(agreement)
AWB: (explanation of how this could work and documented)
SM: Concrete spec proposal and what goes into next release?
- Will need to converge eventually
- Can do it on our own
- Could do this as part of the TC39 process
RW: suggest proposal Future Reserved Grammar doc for next meeting to ask for Stage 0
(discussion about responsibility)
JM: Seems like "type systems of some kind" have interest. Start conservatively, Future Reserved Grammar/Syntax etc, and build from there.
JT: Stage -1: reserved grammar
DH: Stage 0 for this:
- Reserve syntax via Future Reserved Grammar/Syntax
- Does not compute
- Is an error
- cannot ever create an incompatible change
AWB: Make a motion that TC39 is creating an area of research in types and type annotations and all members are welcome to get involved?
DH: As long as we maintain balance and prioritize.
BE: Concern about opening the door too wide.
SK: What about work on extensions that require semantics?
ARB: you can't know what type syntax you need without knowing the semantics. In particular, Python's type syntax as just expression syntax doesn't scale, you generally need different constructs on both levels
BE: for example generic brackets
DH: What is the grammar?
JM: (python expression example)
What's the conclusion?
ARB: make colon syntax reserved
RW: there's more to it!
Conclusion/Resolution
- Create Future Reserved Syntax (extension restrictions)
- Syntax error
- Define
a: T<U>
5.10 global.asap for enqueuing a microtask
(Domenic Denicola and Brian Terlson)
DD: Want enqueue microtask, which is capable of starving the eventloop
AWB: As spec writer, I don't know what this is
YK: In JS there is a frame, it loops
MM: Is the queue, the same queue that promises queue into?
DD: Yes
YK: Want a way to queue a job that's guaranteed to run before all other tasks
AWB: There are spec mechanisms that define ways to create a job in the queue
DD: Don't care what it's called just want it to exprss the intent, which is faster than setImmediate
Discussion about the semantics and defining the order of execution. MM is objecting
YK: A non-normative note?
DD: No, if it's non-normative I don't care, I want it normative
Issues about host interference with expected run-to-completion model
AWB: present job and job queue mechanism intended to describe the two things we needed to describe and knew there would elaboration. Go ahead and develop a proposal.
YK: Concerned that explanation problems lie in using browser terminology
- Micro task is part of run to completion
- Task queue is not
AWB: jobs run to completion
MM: Job queues are always async by definition
- We have terminology, please use the correct terminology
YK: Ok, won't use "synchronous"
MM; multiple queues in a priority mode
- You want the microtask queue to have a strictly higher priority
- We may even specify priority queues
DD: Want to specify global.asap
- Accepts a function
- Enqueues in a high priority queue
DH: Think this is awesome
- We need a generic model for job scheduling.
Conclusion/Resolution
- Stage 0:
- Some way to publish into a queue
- priority queueing
Sept 27 2016 Meeting Notes
Brian Terlson (BT), Michael Ficarra (MF), Jordan Harband (JHD), Waldemar Horwat (WH), Tim Disney (TD), Michael Saboff (MS), Eric Faust (FST), Chip Morningstar (CM), Daniel Ehrenberg (DE), Leo Balter (LB), Yehuda Katz (YK), Jafar Husain (JH), Domenic Denicola (DD), Rick Waldron (RW), John Buchanan (JB), Kevin Gibbons (KG), Peter Jensen (PJ), Tom Care (TC), Dave Herman (DH), Bradley Farias (BF), Dean Tribble (DT), Jeff Morrison (JM), Sebastian Markbåge (SM), Saam Barati (SB), Kris Gray (KGY), John-David Dalton (JDD), Daniel Rosenwasser (DRR), Mikeal Rogers (MRS), Jean-Francis Paradis (JFP), Sathya Gunasekasan (SGN), Juan Dopazo (JDO), Bert Belder (BBR), James Snell (JSL), Shu-yu Guo (SYG), Eric Ferraiuolo (EF), Caridy Patiño (CP), Allen Wirfs-Brock (AWB), Brendan Eich (BE)
Introduction
AWB: Will ne sitting in for John Neumann
RW: Notes at reflector
- Note taking TBD by subject
AWB: Agenda approval?
-
Approved
AWB: Previous meeting notes approval?
- Approved
AWB: ECMA414 Approval?
- Feedback was: missing normative text
- Second edition written to address those issues
MM: (clarifying motivation?)
WH: I had the same feedback when this initially came up in TC39. A standard can't be just a bibliography; it needs to state what it's standardizing. Istvan SEBESTYEN: Waldemar, it is more than a bibliography. It is a compilation of normative and not-normative ECMAScript components, with normative and informative links. What is important that it is standard that will not change every year, and when fast-tracked is fine under the RAND IPR Regime of ISO/IEC. This solves the problem that Ecma will not have to fast-track its RF ECMASCript standards every year, which would not work...Too fast, for keeping the Ecma and ISO specs in synchronization.
AWB: Please look at linked pdf, review and have decision for Thursday
WH: Little bug in ECMA414: What's a "share conform"?
DH: Someone on my team can archive ecmascript.org in a way which is more maintainable. Are we OK with keeping a static snapshot of bugzilla as well as the wiki?
DE: preserve open/unaddressed items?
DH: Looking for approval of snap shot?
- Approval
Conclusion/Resolution
- Agenda Approved
- July Notes Approved
- Snapshot of bugs.ecmascript.org approved
- Review ECMA414
Contributor Agreement for Guests
AWB: Individuals who are not currently representing an ECMA member, please talk to Brian and make sure to sign the contributors' royalty free patent grant.
BT: tc39/ecma262/blob/master/CONTRIBUTING.md , please sign the document listed there
Agenda scheduling
- Proxy integrity checks discussion first thing Wednesday morning
- Node module discussion 11-3 (at least)
- Saam is here for Tuesday, wants to present OrdinarySetPrototypeOf
- Rest/Spread property review not ready Tuesday
- Target 12:30 for lunch
7 ECMA262 Status
(Brian Terlson)
BT: Tooling: Ecmarkup is now much faster, and written in TypeScript
YK: We are writing the Handlebars spec in Ecmarkup, and it is definitely helpful.
RW: We are using it to specify the IO Plugin standard for Nodebots
BT: TypeScript is using it and C# is considering using it as well. The question for me is, what kind of changes does it make sense to add, when there are feature requests that aren't used in ECMA262? E.g., * and + for grammars. My feeling is to add things when they don't compromise 262. I would break out a separate notational conventions document, including * and +, which had all of the features of the tool. This potentially impacts the editorial conventions in 262, though I will work to not require those changes.
WH: I wouldn't want to use * and + in the ECMAScript grammar.
BT: Agree; these are meant only for other languages.
BT: With Domenic, I am working on integrating better with the spec authoring tools in HTML-land. This includes standardizing on a bibliography format so we can share symbols and cross-reference well.
BT: Spec fixes since the last meeting:
- Fix to GetOwnPropertyDescriptors (discussed at last meeting)
- Editorial fixes
- Async functions PR is out
- Editorial flux
- Please review PR
AWB: Any observable changes?
DE: One semantic bug reported
BT: But no major changes
BT: Grammar plumbing in spec, previously "hand waved", but now fully written
AWB: How many implementations are?
BT: At least two
FST: We have full patches, I think that's implementation experience
AWB: If we found bugs, they should be reported
BT: A small bug was fixed
BT: Editorial fix: UniqueFormalParameters is the new StrictFormalParameters
BT: Normative bug fix: toPrecision
BT: new.target/super inside eval; needs consensus?
KG: The spec previously allowed super calls inside functions inside eval, even though they are prohibited by static semantics in the main function
AWB: I believe this is a hanging loose end from when we stripped out super from normal functions
BT: Yes, and it is actually disallowed within arrow functions. It's weird.
AWB: Now, with the PR, there are "static semantics" that apply to the eval that prohibit super in exactly the same situations where they would be prohibited not in eval.
BT: Sounds like we have consensus. Also, same deal with new.target? Good, I'll take those PRs then. There are some further needs-consensus PRs later in the agenda.
AWB: We have two more meetings before ES2017 is done. If there are things that are targeting that release, the clock is running. If there are things in Stage 3 waiting for two implementations, there's not a lot of time left--the champions of those features need to be championing getting things implemented.
SG: For SharedArrayBuffer, we have implementations well underway and fairly mature in multiple browsers, but the memory model is still under development. How should this apply?
AWB: The memory model is part of the spec, and you need this to verify that the implementations match the spec.
BT: From my async function experience, I can also suggest that you keep in mind that the PR to merge into the spec is a lot of work. We may want to put PR work as part of Stage 4 requirements, as the standalone spec often has some hand-waving.
RW: I agree; even for exponentiation, a much smaller proposal, it was a bunch of work to integrate everything and make it all concrete
YK: implementors hesitant when issues are left open, concerns that these maybe long term issues.
SYG: [For SharedArrayBuffer] Implementations will do what will work out for real chips; we have to capture a memory model that other people can reason about, but the implementation won't change since the hardware does something. I don't want to speak for everyone, but I think SpiderMonkey and V8 agree on this.
WH: The bug we ran into was that the memory model formalism was allowing synchronization without atomics; that's not something we want to allow but is hard to fix.
Conclusion/Resolution
- Please review async functions PR
Stage 4 Process Update
BT: Include PR for Stage 4 approval?
"Editor has signed off on your PR"
Conclusion/Resolution
- Editor Sign Off on PR
- Done: tc39/process-document/commit/e0009705959360f35cf44468c5568e9d5bdbae0d
8 ECMA402 Status
DE: formatToParts has been removed from draft due to missing implementation. The only implementation was Intl.js
- Would like to roll back to Stage 3
- Spec can easily accommodate reintroduction
Conclusion/Resolution
- Set back to Stage 3
9 Test262 Status
(Leo Balter)
LB: Small updates, harness, etc. I would like some help on reviewing test262 patches and writing tests, as I don't have enough time for everything.
BT: If used node harness in the past and didn't like it, try it again!
- host specific stuff separated
LB: Need to work on update for TR104
DE: Were we going to retract this document?
AWB: This document is informatively referenced by ECMA 414; Istvan was suggesting to retitle as TR414? (since it also includes ECMA-402 tests) Istvan Sebestyen (sitting in CH...): No, that was a mistake on my side... Sorry... I wanted to keep the original TR number (but 2nd Edition), which I think it is TR/104? I do not have the Ecma TR list in front of me....
LB: Need to arrange further Test262 work
(discussion, re: agenda ordering, etc)
(break)
11.2.f OrdinarySetPrototypeOf fix / Prototype loops and Proxy objects
(Michael Saboff)
docs.google.com/presentation/d/1kHuEtVc-GPp3rbddMVBATKYQ5qLz2o4LnNGUNg8cCz4/edit?usp=sharing
SB: The cycle check in OrdinarySetPrototypeOf bails out on Proxies, which it has to, as it can run any code for the prototype. It's only possible to really validate in that case.
- bug: anything with setPrototypeOf
MM: Does this allow users to detect whether an object is a Proxy?
MS: Let's discuss the feature first
SB: Maybe, we'll have to think about this
SB: The general motivation is to make Window or Location, which use the ordinary get/set prototype methods, but still make sense to have cycle checks for.
FST: We ran into this in Firefox as well
SB: Do we think it's a goal to prevent prototype loops? I'm thinking about cases that use [[Prototype]], which ordinary objects use, and host objects like Window and Location should have these checks as well
MM: disagree, re: proxy
SB: The proposal is: embedders like HTML should have the benefits of this cycle check
- get the benefit of the cycle trap
BT: objects that have exotic GetPrototypeOf should be allowed to have cycle trap?
AWB: You have to be more restrictive than simply an exotic SetPrototypeOf
SB: Can you detect whether something is a Proxy by trying to induce a cycle check?
MM: The simplest stance would be to drop the cycle prohibition altogether, since it can't coherently be enforced
AWB: Spec has no cycle prohibition
SB: Proxy not have [[Prototype]] ...
MM: If circularity requirement dropped...
DH:
- OrdinarySetPrototypeOf does cycle check? Yes
- Impossible to set prototypes with proxy without cycles? Seems wrong
MM: Last time we discussed this, one proposal was to use the [[Prototype]] of the target for the loop checks (going down the target chain as necessary). That's coherent because it proves there can't be an instant in time where there's a cycle.
SB: I think this is not what I'm trying to argue. I'm saying, consider other objects, do we care about cycle checks? I am proposing
MM: w/o proxy no cycle checks agree. But we have proxy, so disagree
SB: This spec proposal is just to keep Proxies with the same behavior, and bail out in that case as we do now, but allow embedder exotic objects to have the cycle check.
Proposal:
As was mentioned in the original bug (comments 9 & 11), a loop check could be performed through ordinary lookup of each object’s [[Prototype]] without trapping to any handler. Specifically: Eliminate step 8.c.1 from 9.1.2.1 Change 26.2.2 Properties of the Proxy Constructor to state that proxy exotic objects have an immutable [[Prototype]] property of null. Remove the comment in section 6 of the possibility of prototype loops.
AWB: to host objects, ie. location. Anything else where host might create, but not using proxy, defining non-standard behavior—there is any easy out. Existing cases are doing checks.
- An exotic object that uses [[Prototype]], can override GetPrototypeOf, but has to be idempotent.
FST:
DD: Doesn't work because document.domain, which allows to change whether window is same origin or cross origin. Window will change from prototype to null
AWB: If you can only change to null, can't create a circularity
SB: Could give Proxy [[Prototype]] of null just for this case
AWB: How?
DD: This would blacklist proxy
SB: some flag? A square-bracket whatever, my GetPrototypeOf should make me terminate the lookup
MM: Using the proxy target's prototype, follow the target's chain?
SB: Would work
AWB: How relates to HTML problem?
FST: Don't know
KG: Instead of whitelisting ordinary objects, we would change this loop for Proxy.
AWB: Decided that proxy isn't the problem.
- issue is non-Proxy
MS: The catch is too broad and catches the wrong things
KG: (Kevin, you had a point here and I missed it, please fill in if you can)
MM: only w/r to the cycle check. Anyway, I see that my proposal does not add value. I withdraw the objections.
YK: I assume you don't want to be able to detect whether something is a Proxy.
AWB: You could detect whether something is a Proxy by <insert exact procedure, which would throw only if not a Proxy>
MM: A Proxy could throw to prevent it from being detected in this way.
DH: Is it sometimes poss if it's a proxy, or
DD: Glad we nailed that down; I think whatever we do here will work with that.
YK: reads are always exact same to Proxy.
- Presently stop you anytime you enter a cycle
- if restriction on the [[Get]] side, always have to do it
AWB: Have now is what we want. Overhead on a [[Set]], which almost never happens. Allows optimization on [[Get]].
MM: I think it's important to note that we have a "yes" for the ability for Proxies to be undetectable
SB: This proposal, with respect to Proxies, is indistinguishable from current behavior
YK: if possible to demonstrate that a proxy can evade, then we need to be aware of that
MM: if proxy chooses to evade, then it always evades. Not all proxies evade, just those that already.
MS: I agree that we don't want to change the observability of whether something is a Proxy. I don't want to go down the rabbit hole of whether we have that or not. We can just discuss whether we change that observability.
MM: Agree
AWB: host objects allowed to define GetPrototypeOf behavior, but doing it in SetPrototypeOf
MS: Discussion is to change on the [[Set]] side
DD: Some mechanism to allow host objects to "opt-in" to this check
BT: an opt-in seems better
- Can blacklist proxy, but then implementations have to think about how that effects
- An additional flag?
AWB:
- Provide hooks in the spec?
- Opt-in or Opt-out
- Problem for HTML spec? It can just say so: "this object must be included in ..."
BT: Let's have a separate discussion about whether we should have either no affordances for HTML, whether we should have prose allowances, or whether we should be completely formal. This should be a separate agenda item.
AWB: Do we need affordance for this particular case?
BT: This case: reasonable for impl to want to have a custom SetPrototypeOf trap for the purpose of stability
FST: We have hit the end of the timebox
BT: Should be possible for impl to impl HTML and ES and conform to the spec. Arguably, Normative prose: an impl "might" say "do circ check..."
DE: Let's put smallcaps MIGHT all over the place in the spec!
AWB: Spec language that checks "has OrdinarySetPrototypeOf", do...
AWB/BT: agree to find some language to resolve? For example, some prose indicating whether a [[GetPrototypeOf]] internal method is suitable for these circularity checks
BT: Or, add an additional slot to all objects that's called [[GetPrototypeOfForCircularityCheck]], which has sane defaults, opts in or out. Allows host objects to set as necessary
BT: Or, Domenic's proposal, give a host callback which you pass the object to to do this sort of check (like the loader hook)
Conclusion/Resolution
- Allow host objects to participate in circuluarity checks
- Need a way to allow opt in/opt out. Editor discretion and review required
- Mark Miller is a reviewer
11.i.a ArrayBuffer.transfer retraction
(Shu-yu Guo)
SYG: There was a proposal to transfer one ArrayBuffer to another, and detach the source. This was implemented in Firefox, and removed. I think no browser currently ships it. I talked with the original champion, Luke Wagner, and he is happy with this.
AWB: The actual design was proposed by Google initially, this was about resizing ArrayBuffers. One use case was drop the size to 0, and the transfer was a kind of realloc. The transfer was proposed as a cleaner semantics
SYG: Originally, this was for asm.js. The particular need for this is reduced by WebAssembly. Given all of these considerations, I am retracting the proposal, in case anyone feels strongly about not retracting the proposal. There is a particular use case for transferring regular ArrayBuffers into SharedArrayBuffers, but I think that should be handled by a separate proposal.
YK: So no one implemented it?
DE: This feature work is continuing under ChangeHeap in WASM, which does this in an instruction, with implementation underway in V8. Also, I think Chakra has some version of this.
DD: Some more context, transferring ArrayBuffers is something we do all the time, e.g., in Streams, which also does resizing
AWB: original motivation was resizing without copying
(This is an updated link to the original gist: gist.github.com/lukewagner/2735af7eea411e18cf20 )
Conclusion/Resolution
- Retracted
10.2.a Legacy RegExp Features
(Claude Pache, Mark Miller)
claudepache/es-regexp-legacy-static-properties
MM: All credit goes to Claude Pache, I am championing this proposal as he does not sit on TC39. I'd like to ask for Stage 1.
MM: The RegExp constructor has always had these bizarre properties like
RegExp.$0. These are spooky action-at-a-distance global communication
channels. The last RegExp match by any RegExp instance in that realm, the
result of the match results in all of this extra information on the static
properties. The good news, historically, has been that we never made it
official, but unfortunately all browsers implement it, and so cross-browser
JavaScript counts on it. At this point, we're better off codifying it so
we're all in agreement on the precise semantics. We went through the same
reasoning with __proto__, and it was great that we did that, as
previously there was cross-browser disagreement. Like __proto__, this
would specified as normative-optional, Annex B, so that environments which
remove it (e.g., SES) can claim to be compliant without this feature. The
properties are specified as configurable and actually deletable. Because a
realm is not in a position to police other realms, this only updates from
changes made in the same realm, and it also doesn't apply to subclasses. We
are only providing this weird, non-local behavior in the narrowest box that
we can, which accounts for what is needed to accommodate web reality.
DE: Big fan of documenting web reality in specs like this, so that people can implement a real web browser just based on specs. seems implementable. realm check not trivial, but possible. Does change things, but worth trying. Will try in canary and assess what happens.
YK: Recently bitten by statefulness of RegExp, lastIndex
DD: (question about matchAll)
MM: Orthogonal to this
YK: Can we make a new RegExp that doesn't have these things?
- Used
const r = /.../gand had state changes :(
MM: No relationship between these issues and the proposal
YK: Agree, was asking if there was a way to downplay existing problems if there is a way to do that?
AWB: Can we also apply this to /u?
MM: Don't believe that use of that feature cuts off spooky action-at-a-distance behavior
DE: Impls shipping unicode regexp, don't want to break web
JHD: This is a refactoring hazard, in case someone adds /u to an existing RegExp
MM: I'm proposing that we leave these on for Unicode RegExps, as per Claude's proposal, which just cuts things off for subclassing
DE: Claude's proposal stashes the Realm on the RegExp in RegExpAlloc, and checks it from RegExpBuiltinExec
MM: We should revisit this mechanism after Stage 1
MS: How should we discourage people from using it?
EF: How about we put that language on MDN?
JHD: Annex B says that programmers should not use the features
YK: In some ways, Annex B is necessary, actually.
DE: We can discuss this proposal without discussing the nature of Annex B
YK: Can we discourage?
JHD: Yes, we already do
WH: The proposed spec has headings such as "get RegExp.$+". I assume that this means that the RegExp object has a property named "$+", but "get RegExp.$+" doesn't really parse as spec text because + is an operator. What formalism should the spec use for referring to these?
MS: is this list the intersection or the union of what browsers already ship?
JHD: based on my previous testing, the intersection
AWB/MM/MS all agree that with verification, intersection is best
Conclusion/Resolution
-
Stage 1 Approval
-
Stage 2 Approval
-
More work needed to come to clarity on the realm issue, namely when realms are saved and checked against what
-
Move repo to tc39
Reviewers:
- DD or DE
- AWB
- BT will review as editor
11.i.d ULEO, Undefined-Like Exotic Object
(Brian Terlson)
BT: Let's discuss intent first: Layering of HTML and ECMAScript. In some cases, HTML hand-waves some prose to do things differently for the ECMAScript spec, or actually has some spec text to replace ECMAScript spec text. Currently, you cannot be conformant with both HTML and ECMAScript at the same time, so browsers choose HTML compliance and are not fully ECMAScript-conformant. There are several issues here, probably dozens.
WH: Clarify?
BT: From a spec perspective, it's not possible to be spec compliant in a browser. Several issues
document.all: an object that appears to be undefined for ToBoolean, typeof, abstract equality, however it's actually an object, and if you array index it, you get properties.- This was born of code written to detect not-IE with
typeof document.all === "undefined", but still useddocument.alldirectly, eg.document.all[0]
(Does someone want to put some examples?)
HTML has some sort of legacy constraints, and to the extent that we want web browsers to have ECMAScript-compliant implementations, those legacy constraints apply to us as well.
AWB: Doesn't bother me that the implementation is a "dialect". What bothers me is introduction of features that specify host implementations, eg. HTML
YK: I think what you're saying is overly broad.
- legacy constraints can be addressed through some other -
DD: We should not be making a spec which is bullet-proof against bad actors in other specs.
BE: Not proposing a general purpose escape hatch for all actors
MM: Can you show the details of your proposal?
BT: believe that it's valuable to have the spec reflect reality of today, ie. HTML in browsers, even if it adds complexity.
- ULEO: do not want to give random host permission to have these and call it conformant
- Link to a specific HTML clause, "if you are implementing this specific spec text, then you can use this, but otherwise cannot"
YK: That would be a cycle in the spec text
DH: We could say, we don't want to add ULEOs in Node, and this upreference would prohibit that. How would that be for JSDOM?
YK: If we give people general-purpose hooks, people may end up getting boxed-in and abuse it.
MM: Do you create a JavaScript platform where users are able to write everything in JS?
BT: I am proposing that JSDOM would not be able to have a ULEO. It would be a spec violation for Node to expose an API for this.
DD: I think that's fine that JSDOM doesn't emulate document.all
BF: I think that's fine; I don't think Node cares
DH: Either nobody wants this, in which case why write it in the spec, or it is wanted, in which case we need to expose it more generally.
BT: No, there's a middle ground
YK/DH: (discussing reality of prohibiting hosts from implementing)
DD: What if we identify this as a mechanism for "legacy host"...
DH: Why do anything at all?
BT: Should be possible for an ES implementer to read this spec and know how
the platform works. document.all cannot be described by the spec.
YK: You can use the V8 API for this from any native Node module?
DD: Yes, unfortunately
BT: Practically speaking, we do not want ULEO to be encouraged to use this feature.
DH: document.all is not something that real code in browsers are having
problems with
AWB: Happy to have the HTML spec handle this, replace ToBoolean
BT: That's what this does
DH: As soon as there is a thing in the spec, it's very hard to stop people from using it. This requirement comes from building a web browser, and it's platonically a real case for when monkey-patching makes sense.
- There is a delta to JS semantics that is the browser semantics
Discussion re: Annex B reality.
- The uplink won't prevent anyone from using it
YK: If we make this restriction and there are other use cases, we can loosen it later
BT: But I don't think there are other use cases
DH:
CM: All for implementors to break the rules if they need?
DD: Where does that stop?
AWB: Annex B is exclusively about things that are already in the language
RW: We added the dunders to Annex B, which were host extensions but reflected reality
FST: Agrees
AWB: But those pertain to Object
RW: Are you keying on document as an entity specified elsewhere?
AWB: Yes, or any
(missed discussion due to etherpad fail, but here's the thing: you don't want to know what was said.)
DH: it's important that we make people feel bad about using these features
Repeated discussion about ownership of this behavior
KG: (attempting to bring it back together)
BT: Nice to normatively "uplink" to HTML spec
BE: So ECMA262 is going to depend on HTML?
BT: Just trying to explain the requirements.
BE: (describes concerns about falsey objects b/c value objects) (eg throwing the baby out with the bathwater)
DE: This is OK, they are both editing some of the same abstract operations, but one is horrible and scoped, and the other is general and clean; no contradiction.
BT: The baby is safe
BT: So, we are in grudging agreement that we do want to make such allowances, with appropriate scoping. Some changes are needed for the uplink to scope it. (recaps changes, will offer for review)
AWB: Let's call it something referring to HTML, rather than ULEO.
Conclusion/Resolution
- Review feedback
- HTMLDocumentDotAllObject
- Annex B
- Revising the introductory text to Annex B
HostObjectDefinePropertyReturnFalse
DD: HTML has WindowProxy, when you navigate: things change. Configurable
properties disappear. Thought we had a fix, Firefox implemented it, had a
signfiicant number of websites that it broke, though it was implementable.
From proposed PR:
This allows host environments which need to override the
Object.defineProperty behavior, for legacy compatibility, to preserve invariants while avoiding breaking web applications that depend on not-throwing when defining non-configurable, non-writable properties on WindowProxy. This does not alter the behavior of Reflect.defineProperty or [[DefineOwnProperty]].
It was not web compatible.
For web compatibility, either:
- HTML could monkey-patch JavaScript, or
- We could modify the essential object invariants
MM: This approach takes the least weakening we came up with to be web-compatible.
DD: The invariants said Object.defineProperty would throw on failure, but in this proposal:
- Allow certain objects to define properties where the operation returns false after failure, but does not throw. tc39/ecma262/pull/688/files#diff-3540caefa502006d8a33cb1385720803R22682
AWB: Why can't we add something Annex B, as we just did? To specifically address this one case?
YK: Why don't we just say that, if a Proxy fails, then it also returns false?
DD: Why?
YK: We used to have a rock-solid guarantee that Object.defineProperty throws on failure, and this is reliable. However, we are now deviating from that.
MM: If we could enforce that, then we would. Firefox tried this, and we didn't achieve web compatibility. I am nervous about this issue too, but it seems necessary.
YK: Then let's make it always return false.
DE: That's probably not web-compatible either
AWB: If you want a reliable check that returns false, use Reflect.defineProperty. Object.defineProperty has been there since ES5. The normal return for defineProperty is the receiver, so it's a big distinguishable value (as false is not an object). It hasn't thrown since the very beginning because of the WindowProxy behavior.
MM: It didn't throw, not because it failed silently, but because it succeeded in a way that broke the invariants, which is worse.
YK: So, this is the best we can do?
MM: This is the best we can do.
BT: The intention is that HTML would define this method, which would...
MM: It can just call the internal define property and then make a decision?
DD: Yes, but pass along all three arguments, because it needs to forward them
DD: I was hoping for a general hook, but OK, we can scope it like this.
MM: only care if the object is WindowProxy and the underlying define failed
DD: Want to check for many cases
AWB: Impl. do this now?
DD: No, they just violate the spec
BT: agrees overly complex. will have to do it as you've asked, but with very specific case rules.
Conclusion/Resolution
- Add the new definition of Object.defineProperty in Annex B, scoped with an upreference to what HTML needs
global (Jordan Harband)
(Jordan Harband)
tc39.github.io/proposal-global
JHD: Last remaining issue was Mark's concern, which is no longer present.
- renamed
System.global=>global
JHD: The spec text is based on calling ResolveThisValue
DE: Should work with whtaever the spec calls the global?
DD: No, need to return the global this
DE: timing wise, problematic to call ResolveThisValue (when is this executed?). The WindowProxy/Window/global object issue is separate, and needs to be resolved with a separate spec change.
DD: Disagree, but confident in Jordan's intent, will not block consensus
YK: For the user perspective: returns
windowin browser?globalin node?
JHD: Yes
JHD: Node semantics are a little different, since it's enumerable and writable.
BF: It doesn't seem like this should be a problem, to make it non-enumerable and configurable and non-writable.
MF: Wasn't this supposed to be reliable? Making it configurable makes it unreliable.
JHD: On first run, needs to be reliable as first run. Can be locked down via SES
KG: if we make it non-writable and there is existing code that does global = 1, that will break.
DD/RW: writable: true, can still be locked down by SES
DE: We should require browser-based web-compatibility evidence before bringing something like this to Stage 4
AWB: This is going to be web-incompatible
(General agreement that we should make it writable)
RW: w/r to enumerability:
search?p=2&q=Object.keys(global)&type=Code&utf8=✓
(Note: this was a misapplication of enumerable, configurable, writable.
Specifically: was not thinking about global the property itself, but
the contents of that object. - Rick)
DE: This should have browser web compatibility evidence before reaching Stage 4.
Conclusion/Resolution
- Change to writable, non-enumerable, configurable
- Will revisit after changes; seems on track for Stage 3
11.i.b Mixins or class extends plain object
(Rick Waldron)
RW: In our Maxmin class semantics, we came to the intermediate conclusion that you can't subclass something that's not constructible. However, should we reconsider inheriting from objects?
MM: We did this because we realized that we could make a function that returns a constructor for this object. This was a nice aha moment.
Discussion, re: mechanisms that can be written in userland code today.
RW: But this creates a bunch of extra lifting that they have to do; why can't they have this in class syntax? Do we want to try to solve this problem?
WH: This is like asking, why can't you subtract two strings? What does that mean?
YK: It would be nice to the community to come to a more crisp answer.
RW: I did present these things to the community about how to do things, but got feedback that that seemed like it was a hack.
YK: Our crisp story: Our class syntax is for subclassing a class.
RW: The alternative I proposed was actually even smaller than the example that they gave, where the mixin would be based on a superclass with methods.
EF: I recognize that there are no proposed semantics at the moment. Is this supposed to actually be syntactic sugar for synthesizing the constructor, getting super semantics, etc
AWB: super semantics work out just fine with a parameterized class [function that evaluates to a class]
DD: There are a lot of notions of mixins; let's scope this discussion to 'classes extending objects'
YK: Actually, extending objects reintroduces all of the ambiguity of ES5
BF: Let's take a step back from the syntax, and from making this on classes. People want mixins. People want to set the prototype of something. They have a big grab bag of objects, and a big grab bag of things they want to attach with a prototype. They see that class is a way of setting the prototype syntactically, in a manner. I'm asking, do they really want it on a class, or do they really want this syntactic prototype delegation? proto feels like a second-class citizen.
RW: My question to this room is, should we put time into the syntax like class-mixin-basic.js?
YK: Can already synthesize this today by using class A extends obj(O) {...}
YK: Seems like there should be a really compelling reason, since it would just be a few lines of code to make a function which synthesizes this constructor, instead of being built-in.
MF: Is this proposal dependent on this particular syntax, or would you be open to using a distinct syntax for using this?
RW: I just want to raise the general discussion. Would the committee be interested in pursuing this concept of inheriting from an object?
BF: I'm not in favor of this current proposal, with a runtime check
DE: Can we discuss mixins generally?
DD: In a separate topic
WH: I'm pretty convinced by Yehuda's example that this feature is not needed.
DD: However, we are generally interested in mixins
SM: You might want to have static methods on your mixins. You may also want to have super calls in mixins. React has to interact with whole ecosystems, like Scala.js, which doesn't have the ability to inherit from super. I would not want to encourage these patterns proliferating.
Conclusion/Resolution
- Committee is interested in mixins, but this particular proposal is not a direction we want to go in
11.i.c Generator arrow functions
(Brendan Eich)
BE: We passed on generator arrow functions after looking through a few alternatives. The only one that seemed feasible was =*>. We passed, and
said "revisit for ES7". But actually, people are writing code which uses function*() {}.bind(this)--once you're in class world, you want instance-bound this.
(General confusion about the example shown)
DH: call it back to order, this is too distracting because too much going on \
- refocus on generator arrows
DH: Here's a case where you have a generator which closes over this: tree traversal
YK: closing over this in the generator is more prone to leaks
BE: It's not closing over in the generator, it's closing over in the constructor
BT: Maybe we want an auto-binding declaration form
MR: Don't all these arguments apply against arrow functions in general?
BE: We had ASI issues with some things, but the version that works (in the middle)
- x => x + x
- x =*> yield x + x // missing (obvious?) combination
- async x => await x + x
RW: There is also:
- `* (x) => yield x;
... But has ASI
JM: problematic with multiplication: var a = foo * (x) => yield x;
DH: Adding syntax is serious business. We're not taking the union, but the intersection, of these use cases. How often do you need a callback that's a generator function? Each feature needs to pay for itself.
DD: This composes nicely for async generator arrows: async x =*> yield
await x
JH: This kind of pattern shows up in observables, so it could have more utility
DH: syntactic sugar should map to strong idiomatic programming concepts, not just for the sake of having all combinations.
DE: Jafar made the case that this is a nice pattern
Too much disagreement?
BE: The case for arrows was strong; this comes up less frequently, since it's for callbacks which bind a generator function.
AWB: In the context of the method pattern like
class C {
method = (args) => {
...
}
}
The generator arrow makes sense as being analogous
WH: Don't like =>. At the very least, we should use => instead.
BE: No, that syntax doesn't work; See the notes from the Nov 2013 meeting
WH: [after looking at notes] The rationale from those notes no longer applies since we're not using ! for async arrow function syntax. We can use =>*
BE: Now agree. We can now use =>*
DE: Doesn't this prohibit * as a prefix operator for the future?
MF, WH: Already taken by yield*
DD: Path foward: Write out this case, with all the justifications, and explaining why the alternatives are not true; find existing user libraries where it'd be helpful to have a generator arrow function, etc.
JM: This case comes up not just for Redux Saga but rather whenever you have a callback which is a generator
DR: You need to create some kind of closure for these sort of situation
Conclusion/Resolution
- There is some interest from the committee, but concern that the feature does not pull its weight for adding a new piece of syntax
- Plan to revisit on Day 3 to see if we can get =>* to stage 0 at least, as
part of DD's async iteration proposal
11.2.a Named Capture Groups
(Daniel Ehrenberg)
Slides: docs.google.com/presentation/d/1b3CigDqepiupv7jQbHyKVkRG72t2qIxeN_DnX75jTY8/edit
littledan/es-regexp-named-groups
DE: (presents from slides)
DH: IdentifierName, not Identifier
WH: Named back-references have nothing to do with Unicode; would be much happier if they were usable in any regular expression. The question we don't have enough data on is whether this would be web-compatible.
Discussion of syntax, there are alternatives
Discussing
let re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
let result = '2015-01-02'.replace(re, '$<day>/$<month>/$<year>');
KG: A web-compatible option would be to make \k be k in legacy regexps
unless there is a (?< in the regexp.
WH: Yes! That would be web-compatible for non-Unicode regexps.
BT: Any data collection on \k, also collect data on all escape sequences
\k<?
BT: valid today?
Yes
DE:
- \k not available in non-Unicode RegExps (backwards compatibility)
- Option: Python-style backreference syntax (?P=name)
- Option: Revisit (with data) whether it’s possible to add this new escape
DE: group names overlap with of match object
- Early Error
- Put names in separate inconvenient "groups" object.
DE: Can develop as early error that can be revisited
JHD: Can we prefix with $?
Properties:
- length
- input
- index
littledan/es-regexp-named-groups#overlapping-group-names
Conclusion/Resolution
- Stage 1
- Property Smashing
11.ii.e Unicode property escapes in regular expressions
(Daniel Ehrenberg, Mathias Bynens)
docs.google.com/presentation/d/1o31S9RqDdkoWW2zfPMNIZdPDIp25Rr0-XW0gro_cskk/edit#slide=id.p
DE: Why \P
- The Unicode Consortium’s UTS 18 recommends it
- All other programming languages surveyed follow UTS 18 here
- According to Mark Davis, there are many overlaps between property values and keys, so clever abbreviations are not recommended
DE:
- Disallow extending Unicode property support for optimal interoperability mathiasbynens/es-regexp-unicode-property-escapes/commit/4a5f49d19eb5651467e04d84c660a6230dad8334
Conclusion/Resolution
- Stage 2
- Reviewers:
- Bradley Farias
- Waldemar Horwat
- Allen Wirfs
Sept 28 2016 Meeting Notes
Brian Terlson (BT), Michael Ficarra (MF), Jordan Harband (JHD), Waldemar Horwat (WH), Tim Disney (TD), Michael Saboff (MS), Chip Morningstar (CM), Daniel Ehrenberg (DE), Leo Balter (LB), Yehuda Katz (YK), Jafar Husain (JH), Domenic Denicola (DD), Rick Waldron (RW), John Buchanan (JB), Kevin Gibbons (KG), Peter Jensen (PJ), Tom Care (TC), Dave Herman (DH), Bradley Farias (BF), Dean Tribble (DT), Eric Faust (FST), Jeff Morrison (JM), Sebastian Markbåge (SM), Saam Barati (SB), Kris Gray (KGY), John-David Dalton (JDD), Daniel Rosenwasser (DRR), Mikeal Rogers (MRS), Jean-Francis Paradis (JFP), Sathya Gunasekasan (SGN), Juan Dopazo (JDO), Bert Belder (BBR), James Snell (JSL), Shu-yu Guo (SYG), Eric Ferraiuolo (EF), Caridy Patiño (CP), Allen Wirfs-Brock (AWB), Brendan Eich (BE), Jacob Groundwater (JGR), Adam Klein (AK)
ES Modules Lifecycle
(Bradley Farias)
BF: We will be talking about host-dependent behavior: The Node module loading hook is specified in a way that meets ES spec requirements. There is a global and local cache <explain details>
(from slide)
Resolve (as absolute URL) => Fetch => Parse
- Make Module Record
- Place in Global Cache using Absolute URL*
- Errors remove records from Global Cache* Traversal of import declarations recursively
- Ensure step 2 has been performed on the dependency
- Place dependency in Local Cache using Import Specifier*
- Link dependency to module
- Errors prevent any evaluation Evaluate in post order traversal
- Errors prevent further evaluation
CP/YK/AWB: (There are items here that are strictly host-specific)
BF: Necessary for Node
DD: for example the local cache is not required by the spec; we don't have one in browsers
BF: agreed.
DH: Inherently, dynamic module systems that would want to interact with ESM need a late linking mechanism. Another option would be to delay linking for everything. I would be open to this option. It might not preclude reasonable implementation optimizations.
YK: And modules haven't shipped anyway
AWB: Appears to be an "interpretation" of the requirements, but we need to understand why
- e.g. local caching? Why required?
MR: We have caching; we need it
BF: [~Lifecycle Errors slide]
// a (entry)
import {fromB} from 'b';
import {fromC} from 'c';
// b
export let fromB = 'b';
// c
import {fromB} from 'b';
// FIXME
import {doesntExist} from 'b';
export let fromC = 'c';
throw Error();
BF: This causes a link error. no evaluation occurs. B exports to A, C exports to B, and we fail. To implement this in Node, we store things in the global cache, and remove when there are errors resulting.
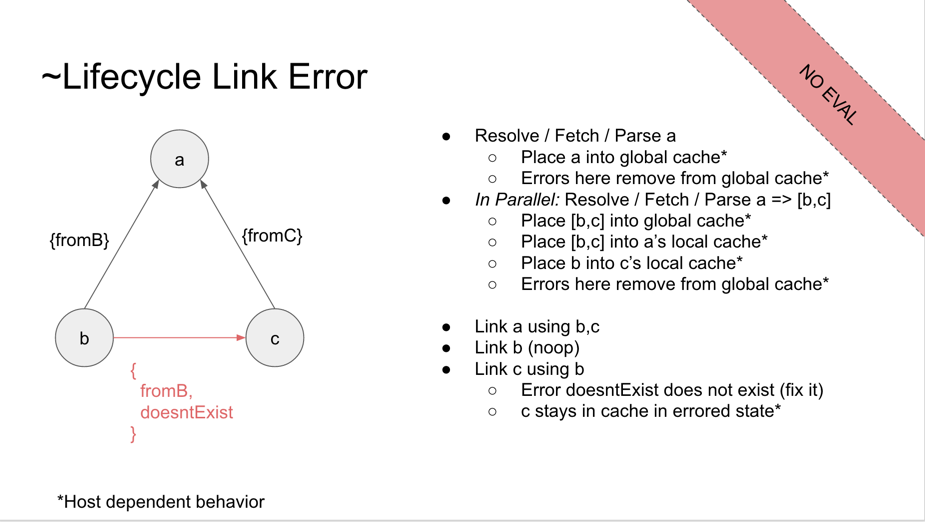
WH: What do you mean by placing b,c into a cache?
BE: It's not a cache; you can't miss. Sounds like the cache would be more accurately be called a table, since you insert things in for a real effect.
AWB: The spec text states when the link error occurs, it all goes away
WH: All of A, B, C disappear?
(confirmed)
DH: I didn't think there was anything in ES2015 about error states, global semantics of the registry
AWB: When you reach an error, it throws, and it unwinds to the old state
DD: Actually, the idempotency requirement is strong. Firefox found a bug in the initial HTML/Modules integration where we violated that requirement, and it caused us to make changes to unwind the state
DH: The slides discuss the idempotency requirements?
(confirmed)
BF: (remove FIXME)
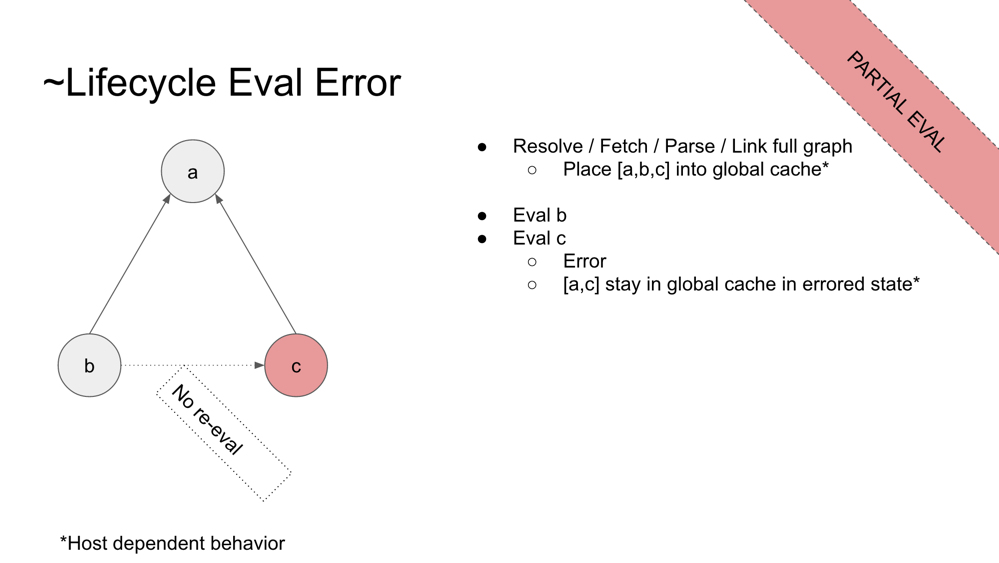
AWB: The top level was aborted before reaching the end, and result was...?
BF: One function of the cache is to make sure the module evaluation only occurs for the first time the module was imported, and not again on subsequent imports
BF: [~Lifecycle parallel loading slide] Diamond imports. We actually plan to evaluate in the order d, b, c, a
AK: Why are the linking and evaluation orders different?
BF: The linking and initializing bindings steps are logically the same
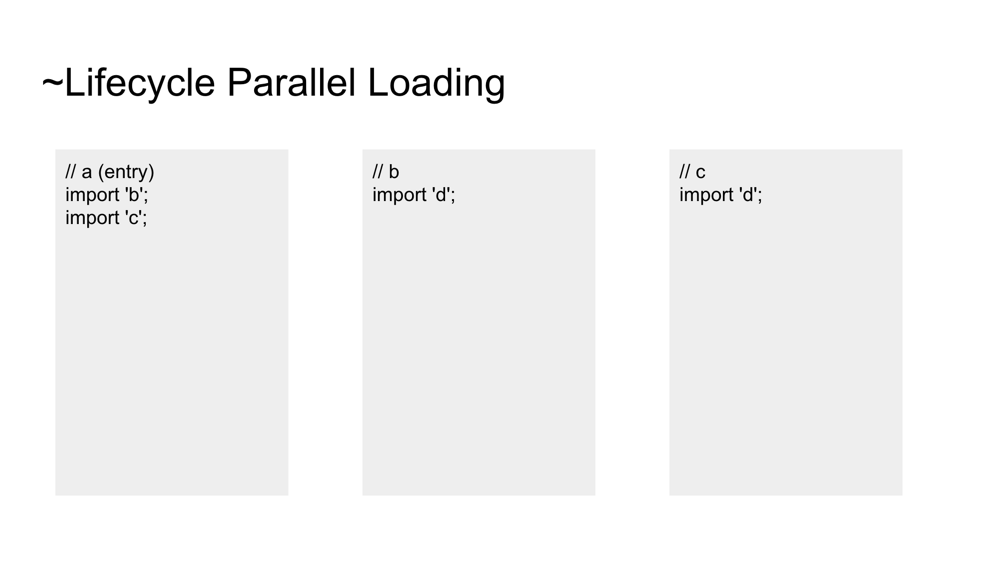

YK: Spec bug? If hoistable decl and linkage occur in wrong order?
WH: Can anyone produce a concrete example of where this matters?
BF: This...
(Note: this is far in the future of the deck)

BF: [Timing example - hoistable] After linking, functions are available to be called [since functions are hoisted]. If we get some things wrong, foo could be undefined when we try to call it.
AWB: This can't happen.
YK: Is this related to cycles?
BF: Most of the problems are related to cycles, or things that cross them
YK: If you have a cycle, make sure the hoistable decls are evaluated ...?
BE: How observable?
BF: In pure ESM, you never run code before it's completely linked, but when interacting with commonjs, we have to be able to execute some code earlier.
DH: ES2015 does not cope with dynamic modules.
BF: If we have any interop, the distinctions between
BF: let's go back instead of skipping ahead a bunch of slides
AWB: Need to understand differences between static and dynamic per spec.
BE/DH: need to address interop, dynamic code that can execute before link
BF: CommonJS/ESM interop: conceptual distinctions are fundamentally at odds, material distinctions are at odds due to spec/implementation details
AWB: Conceptually, ESM is based around sharing bindings, whereas CJS is based on sharing values

- Conceptual: intent or design goals that are fundamentally at odds
- based on notes, records, design, etc.
- Material: specification or implementation mandates that are at odds
- based on things in reality
WH: Why are conceptual and material required to be at odds by definition?
AWB: clarify? "conceptually" ES modules are based around sharing of "bindings" vs commonjs sharing of "values"
BF: More than that
BF: There's more than that in terms of conceptual differences
YK: We were intending for the loader to fill that gap
BF: Conceptual difference: Mode detection: The spec expects things to be declared out of band; this could be a grammar change
BF: Material: Some cases are ambiguous. This isn't the most important issue.
BF: Cache data structures: We will have module maps analogous to browsers
DD: This is what enforces the idempotency


BE: Can you unload from this?
BF: From given module record, import some string it's permanent: cannot remove it.
AWB: depends. linkage errors you could
BF: expect to completely recreate your dep graph
AWB: once mod is instantiated and linked into the system, it's in. If not past the point of linking, then no one has seen it.
YK: the discussion on es-discuss could've gotten it wrong?
DD: There was a conceptual goal of idempotency
DH: A thing in the spec, but not especially understood.
DH: consequence of things dissappearing at error? avoid surprises. need complete control in your program. Not always automattically forced into reload policy. If the spec says reload, then issue.
DD: The spec doesn't lead to reloads; it leads to permanent not-reloads.
DH: Doesn't deleting from the cache cause a reload?
DD: the semantics say: once you get an error, you must cache that error forever
DH: Sounds like we should add more features for control here
YK: Is an issue that node needs to be things to go away
(fell behind)
BF: example: a mocking library that wants to replace things in cache
JSL: The default behavior in Node is to get the same behavior back once it's initialized
BBR: We want to avoid many cases of getting two copies of modules, though it's not always possible, e.g., case-insensitive file system and different case names.
AWB: if you have file path: import a from path, you retrieve, link that in; subsequent import of the same string returns the same thing.
DH: clarify: a post resolve name?
- Can't specify anything about strings that appear in the
(I didn't hear the end)
AK: Unfortunately, the spec does talk about those strings
AWB: What the spec says that if two strings are pointing to the same thing, it should be the same module
YK: We should fix the spec if needed
AWB: Want two identical paths to produce different modules
JSL: eg. mocks, instrumented modules
MRS: Some development tools explicitly control the cache, e.g., blow it away
AWB: things like repl loops are outside of the spec. But if you have two imports with identical strings, then under what circumstances would they produce different things?
DD: Discussion reiterates the following points a few times:
- Per spec, the only requirement is that if A imports "x" multiple
times, it return the same module. There is no requirement on A importing
"x" vs. B importing "x".
- However, some people believe that the spec should be talking about
the "normalized" or "absolute" form, not about the literal string ("x"
above) that appears in the import statement.
AK: In the specification, the third bullet in 15.2.1.17 has the idempotency requirement. There is no normalization
This operation must be idempotent if it completes normally. Each time it is called with a specific referencingModule,specifier pair as arguments it must return the same Module Record instance.
(hostility towards note taking)
DH: Idempotency constraint not about source text, about result
WH: So where is the result used in the 15.2.1.17 HostResolveImportedModule •3 idempotency constraint? That line uses the string, not the result.
DD: Layering-wise, there's no way that we could enforce the idempotency requirement about any sort of normalized form, as this is done within the spec based on the name used to address the module in the source text.
DH: Thank you, good to know that the idempotency requirement is about the operation of HostResolveImportedModule, utterly impossible for node?
DD: the idempotency requirement is: if you have two import "x" in the
same file, they must produce the same thing
DH: just a narrow constraint
YK: The intermediate string is where people are thinking about the api
BF: This is a fine constraint for semantics
DD: Bradley's implementation is based on a map, as shown in his slides. The constraint of the spec means that,
if you want to use a map to satisfy this requirement
MRS: To get back to the core point, with Domenic's interpretation (i.e.
that the spec only restricts that import "x" twice in the same file must
return the same thing), are there any problems this?
BF: No, no problem. We can implement this; I was just explaining what this is.
BF: [Cache data structures slide]
BF: Using import() to illustrate

AWB: Remember that import sets up bindings
AK: The example would be identical if it said import "f"; import "f"; in semantics
BF: The idempotency is prior to any evaluation. ESM import declaration links prior to evaluation, so idempotent prior to evaluation
- CJS declares its exports occur during or at the end
AWB: Doesnt matter what you did for exports, nothing to link.
BF: let's say I have import "foo"
AWB: The difference between import and require is that require returns a value, so as long as you get the value, you have it, unlike linking bindings and pre-initializing them
BF: The current feeling of how modules work is based on the Babel implementation, where that is not quite true. They use member expressions for variable access, rather than creating bindings
- using member expressions to simulate live bindings for variable access, not making bindings
YK: Babel might be leaky, but it allowed people in node to do things that need to be understood
BF: [Timing slide] ESM was designed for async loading, conceptually

AWB: My primary spec goal was static linking; I wasn't thinking about async linking at all
YK: AWB's spec is well written to separate the steps (re: sync and async are irrelevant)
BF: To import CommonJS, you need to know their shape, which occurs during evaluation, after linking. For an ES module to import a CommonJS module, we need to hoist the evaluation of the CommonJS module into the linking phase
AWB: So if you want to treat a CJS module as an ESM, you can think of it as <?>
BF: You still need to perform eval at some point
YK: b/c cjs modules need to be evaluated to know what the exports are, and have to evaluate esm, the cjs modules have to be run first (declarative vs. non)
DD: All agreed, evaluation has to happen first.
YK: CJS always treated as a single export
JM: Do have an object before evaluation, can be clobbered. You don't know the bindings ahead of time. If you import a CJS module from an ESM, you can make the semantics be that your lookup of the name is dynamic in a similar sense to the live bindings from ESM.
AWB: When import something from another module, taking bindings that aren't initialized
WH: What is import *?
import *doesn't import everything...
DH: Doesn't exist anymore.
CP: If you happen to have a module that is not esm, can create binding that is default
BF: These slides are based on the intent that we would have the same level of compatibility as Babel, where you can have named imports from CJS. We'd like to not lose that.
CP: not a requirement
YK: desirable
- Have to allow evaluation before linking
DD: Allow him to get to the slides...
BF: Without eval occurring during linking, we have no path to transition from transpilers to native modules.
BF: [Timing example - Circular] Circular dependency between CJS and ESM,
with module.exports = null from CJS

YK: Is this a realistic example?
JSL: Sometimes people do actually blow away exports from within the module
BF: entry is our commonJS, dep is ESM. Dep tries to link, but entry's shape is not finalized. We can snapshot the shape at the end of the evaluation, but we can't link it earlier as we don't know the shape.

AWB: is the problem circ deps back to CJS?
BF: You run into this sort of issue whenever you cross the bridge.
AWB: Requiring a dep starts a new root level load of the module. Not an import.
BF: expectation is that esm cannot import cjs?
AWB: circularly.
DD: Could you clarify?
AWB: requires in context of esm cannot introduce circlularity because hey are binding based, not value based
DD: Can get an evaulation circularity
AWB: Can get a loop or an error
YK: banning cycles between cjs and esm seems more palatable
BF: An alternate solution: Making loading esm from cjs an async op. This makes it so that you can't do eval circularly. This is a pretty drastic change, as some of your loading is async, so your whole dep graph is async
YK: would node consider disallowing cycles between cjs and esm?
BF: Disallowing (throwing on attempt) was part of the original proposal
BBR: fine to drop support for circular deps?
JSL: Circular dependencies are actually very common with require. We cannot get rid of that. There is something to be said that, once we do an import, that we can't do a circular dependency back to require; maybe we can get rid of not allowing that
DH: This is not as drastic as getting rid of cycles altogether.
MRS: at scale?
BBR: Packages can actually be circular
MRS: essentially opting into once you have an import?
DD: Not the deps
DH: only within one package, if cjs package and want to migrate to esm: must migrate all within the package
DD: How does npm install circular package dependencies?
JS: It flattens the loop
DD: It would be interesting getting data on circular dependencies in npm packages
MRS: npm3 makes this worse by circularly depending on things flattening implicitly
JSL: There are multiple problems: When you do change the exports (insert explanation)
BF: The two things which come up the most for Node CTC:
- Named imports being supported in whatever fashion for import <named thing> from CommonJS
- Can we do something synchronously? require(ESM) synchronously returns
the module namespace object
That's mostly what this is about.
JSL: We could implement the spec as is. But this would make some compromises for the usability. With the current spec, these things wouldn't work.
DH: Design constraints: - It needs to be possible to import named exports from CJS - require(ESM) needs to synchronously
JM: Are these technical needs or ecosystem needs?
JSL: These are ecosystem needs. Babel today can do these things. Those users will want to be able to not change their code. If we say that doesn't work, we're violating a concern.
BB: People won't want to upgrade if they don't get synchronous require
DD: Some of these things are up for debate; maybe it doesn't need to synchronously return
JSL: We could also let require this return a Promise
BM: Async is a way to get out of these issues, so you get out of "the zebra striping problem".
(Do we need to be able to import CommonJS from EJS?)
JSL: Maybe we could sell, if it's a CommonJS, we can't import it.
MRS: That's easier to sell to Node people, but it's probably not what you want if you're an advocate of ESM. This will make the transition to ESL a hard sell for new users.
YK: any upgrade to esm, must break back compat.
JHD: a major semver release
DD: talking about named exports? If to make it work it would be an object not bindings? That's not a route we want to go
MRS: We're going to have mix of these two module systems for ever
DD: So, then do we want to get rid of static constraints?
DH: Do not want to throw away the guarantees from static constraints
AWB: With babel's loose interpretation of ESM, you're able to take a CJS module, apply its semantics, and it mostly works
BF: It uses CJS under the hood, with ESM syntax
AWB: In the spirit of migrating, maybe just do exactly what Babel does?
BF: are you suggesting we use the syntax of ESM, but not the semantics?
AWB: transpilation
YK: What node is discovering, esm and cjs is one big graph, other mdoules not considered
AWB: Babel translates ES module binding semantics into CommonJS value semantics
(discussion re: bridging from cjs to esm)
AWB: Not just syntax, fundamentally different semantics
BF: But community things about modules as CJS
DH: concrete level: live bindings, aliasing
?
DD: Adding new properties or deleting old properties
YK: Changing exports by mutating properties
JSL: People mutate the object
AWB: With binding semantics, you can't look at a binding that hasn't been initialized. With value semantics, you look at everything as properties, you may see things as undefined
JSL: The community would really want named imports
BF: We are here to discuss the problem. For timing, we have fixes, for named imports, we are here to discuss
JM: Sounds like we're going to break Babel somehow. We should be discussing how we will break Babel, but rather what's the way to break Babel that's minimally invasive.
YK: Could we make the exports object the default one, and sometimes make some of the bindings get additional redundant names?
DRR: as soon as named export plucking, make it non-trivial to move from cjs to esm. as soon as switched, one of two naive approaches.
- (I'll ask Daniel to fill this in)
- instead of assigning
module.exports, I'll doexport function() {}over and over
JM: Third option, if there's no default export, Node could create one
MRS: It already does
YK: Maybe we could ask users to run a tool when upgrading
DRR: It would be hard to get the tool to be run
MRS: This would be a Python3-style incompatibility
BF: skeptical that we can put in loader?
MRS: vast majority of modules will not be upgraded, more worried about these and users having expectations that they are
BBR: allow two different entry points, if package maintainer wants to do that?
- Or a tool that requires it, looks at the exports and creates a wrapper?
BF: Not sure?
BBR: We accept that there is no automatic transition
MRS: We want to avoid module authors doing any explicit work
BF: If default is
DRR: (fill in point)
DH: important to look at named imports and exports that don't change, vs. do
MRS: (spoke to fast for me to follow, but basically something about
module.exports = function() {}?)
BF: If we had a way to observe mutations, we may be able to track them, but it's not clear how we would do that
YK: Empirically, most modules don't do mutation.
MRS: Module authors will get bugs reported to them that claim the issue is the new version of Node.
AWB: It's clear that all of the CJS and ESM lumped together will not work perfectly, but we can example things for use cases. Some may be automatic, others for tools, others impossible
MRS: We are trying to make these tradeoffs, but we want to make them in a sane manner; we want to look at whether which things would break the spec, or break what things on what end. We think users have a reasonable expectation to be able to do named imports from CJS modules. We will have to sacrifice some of the linking features in ESM, since Node's load cycle is a big block. We need to be able to break the tradeoff without violating the spec.
YK: approach, get as close to the spec as possible, and come back to the committee with concrete points that need to be fixed.
BF: [Hoistable fix slide]

BF: you currently have access to calling the functions defined in a module even if you never evaluate it at all. In this proposal, that behavior would be removed, and you'd only get the functions if you really do it.
AWB: introducing new hypothetical API, need to define its semantics
DH: The observable difference is about whether you encounter
AWB: This only happens from circularities
AK: This is all about the interaction between circular dependencies between CJS and ESM
YK: Why care if esm can or cannot see cjs
BF: We want a single module system that can be used for ES
I'm unable to type fast enough to keep up with this. Its hard to tease out the point when people start and stop statements mid-statement.
I want to explain, I'm going to, Here's how I think we can explain, let me unpack (interrupted)
DH: [suggesting some design where we "delay validation" of imports across module system boundaries]
AK: That would be a big change; it's hard to understand what that would mean.
DH: We may want to insert a lot more dynamism to solve this issue
MRS: How should ESM -> CJS -> ESM work?
CP: you would have a couple stripes when crossing the boundary
DH: That's why it's called zebra stripes
(break)
BF: Linking is very dynamic. The popular npm module "meow" relinks its parent. Used for CLI. When you require it, you get a new particular module per importer, which gives a modified version of it. We may need to revisit linking to support this.
WH: What does this achieve?
BF: This lets you tool out your CLI without knowing anything about your dependent. It lets your dependency learn about your module by reading its package.json.
BF: [Named imports slide] ESM cannot do named imports from CJS dependencies without mitigations. Our proposal is to hoist evaluation of the CJS module up to the linking phase.
JSL: No matter what we do, we will break Babel somehow, the question is just how.
BF: In our current proposal, we would take a snapshot of the exported properties of the object and export those names. We had considered more flexible behavior, but it seems unworkable.
CP: How many people are using this?
JSL, MRS: Some? It's unclear how many rely on it.

MRS: We could say that it just doesn't work properly if you import it as ES6.
BF: Common on npm: "import {Component} from 'React'".
ESM Doable needs
-
Context:
- Remove existing "magic" variables
- Built-in module like
import {url} from 'js:context'to get these variables -- defer to iterate on details, relates to discussion in Portland - Early errors from non-existent context variables
-
Hooks:
- Need to ensure hookup prior to
-
Some kind of loader spec, maintaining invariants of es262. May be related to the loader spec.
----- Discussion Context syntax details
BT: There was earlier discussion about import.context which would be a grab-bag object for these things like these, championed by Dave Herman at the Portland 2015 TC39 meeting
DE: If you want early errors, rather than getting undefined, then we could
have import.url rather than import.context.url which would have an
early error if you did import.foobar.
DD: It is important for this to be host-extensible and not introduce desktop concepts to the web
JSL: Yes, there should be compatibility between Node and the Web, and we'd be open to trying to move away from Node-specific APIs.
MSR: For extensibility, there are various cases, bundling loader, etc. These may hook into this in various ways.
YK: I'm concerned about compatibility with filename and dirname
BF: Although the spec would allow it, we will not modify the absolute URLs. The main thing we would need is import.url; we may want another path for CJS metadata, but no other properties shared between environments.
DH: I'm skeptical
MRS: dirname may be useful for a case where you have templates that you want to load from the directory where the JavaScript file is
DD: This could be based on require.resolve within the Node ecosystem
DH: In the loader spec work, there have been cases where import.url would not be such a clean thing to expose--for example, there could be two names that correspond to the same module.
import.resolve is another proposal for a pseudofunction, taking a string literal or possibly a runtime string value, for resolving the absolute, rather than relative, path which gives a more canonicalized way to reach the module, which would also be a thing that could be passed into import.
Generally: There is agreement in the room that getting the url and having a way to resolve an import into a url are important problems, and some subtle questions remaining about whether it should be a built-in module or pseudoproperty, as well as other details.
DH: New interoperability linking suggestion: The validation to linking would not always be performed statically, but rather dynamically when hitting a CJS module, and in that case, deferring the invalidation until the beginning of the execution of the top-level ESM module body. The next part is, what does the dynamic validation look like. One option is, we preserve live bindings from CJS, and the other option is a snapshot. The latter option guarantees nothing disappearing, but this loses the aliasing semantics of ES6. This is all for the case of importing a CJS from ESM.
BF: There's a difference between snapshotting the list of property keys, and snapshotting the values of properties. I have proposed doing a live binding to the list of property keys which are available as one is exported from a CJS module after the initial evaluation, but to have bindings that are live from the CJS object to the module namespace object or direct usages
AK: The Babel version does have some notion of live binding [because it translates named lookups to member expressions on the exports object]
BF: e.g., used in Promisify.all. Changing the values is much more common than changing the keys.
WH: Trying to pin things down. What is the specific evaluation order of an ESM module A importing from an ESM module B, and what exactly changes if B were a CJS module instead?
AK: [described DH's previous proposal involving delaying resolving bindings imported from CJS into an ESM until after CJS evaluates during evaluation]. Example:
// a import {foo} from "b"; import {bar} from "c";
// b export let foo = 1; console.log('hello');
// c console.log('world'); module.exports = { bar: 2 }
Instantiation of a causes instantiation of b, but because c is a CJS module we defer its "instantation" till later (and in the meantime put the "bar" binding in a into TDZ) Evaluation of a immediately causes b to evaluate (before evaluating any of the statements in a), then c to evaluate, and after c evaluates we can complete linking of a to c, thus initializing "bar" to 2. If c failed to export "bar", then an error would occur at this time (before any of a's statements execute).
DH: Another possibility, more ambitious: We may be able to allow cycles, based on some reordering. Disallowing cycles would be an adoption hazard. The proposal here would require the earlier modules to fully resolve before the later modules come.
JSL: Tools can create cycles that didn't exist
AK: How?
MRS: A downstream dependency may end up adding a dependency edge to something that uses it very indirectly, and a module in the middle of this cycle might not know about this but be affected
AK: Cycles would not work with the idea I was describing before as requiring the ESM from the CJS that imports it would hang, as require is synchronous and wants a fully-formed answer immediately. Options include CP's making the namespace object partial, or returning a Promise, or Dave's changing the evaluation order.
[AK: lots of discussion about a cyclical dependency graph involving CJS and ESM modules; q: how does evaluation order change? a: in several ways. q: do we know anything about the shape of the ESM modules themselves? a: not if there are StarExports that cross that boundary]
Prohibit export* of a CJS module from an ESM module.
BF: We shouldn't return different shapes of modules at different times, e.g. if an ESM module imports a CJS module while CJS hasn't finished evaluating
JSL: We do support that in CJS right now, as a side-effect of how require works
AK: It should be a dynamic error to try to import * from a CJS module if that module is in a purgatory state
AWB: Or we could relax the immutability of module namespace objects in a case where the imported-from module is dynamic. The immutability was mostly for optimizability.
AK: Couldn't there also be security issues with allowing a namespace object to change after creation?
AWB: With everything being ESMs, we can do static resolution all the way down to the base binding. We can't necessarily do that when we have dynamic CJS modules in the middle there. We have to stop at that point. Seems like that requires a spec change. Ultimately, I think TDZs take care of it, but at present, in the ES spec, we assume that we can go all the way to the end, as opposed to going through multiple steps.
11.3.a import()
(Domenic Denicola)
domenic/proposal-import-function
DD: Presently, all module loading is done statically, top level. There are cases where you absolutely need to have conditional imports. There are many common use cases. Need to dynamically load a module, with a string. Returns a Promise for a module namespace object. The proposal keeps with out general stance of keeping proposals small; this is mostly syntax plus calling out to embedder hooks.
AWB: Does the occurrence of import turn the script into a module?
DD: Initially, I thought to restrict it to modules, but no reason to restrict it.
BF: Many reasons to include for use in Node
DD: Good way to bootstrap into modules
AWB: Why special form, not a function?
BF: To give you a context
DD: Want to be given a module specifier, e.g., for some embedders, a relative path which is resolved based on where you're calling this from.
domenic/proposal-import-function#an-actual-function
domenic/proposal-import-function#a-new-binding-form
DD: This is better than inserting <script type=module> tags dynamically
because it's based directly on module specifiers, easier to use, doesn't pollute DOM, etc. Not introducing a new binding form.
DD: New embedder hook, HostFetchImportedModule (runtime equivalent of [[RequestedModules]])
WH: import( is not currently legal, so there's no ambiguity with import
declarations
RW: Channeling DH from three years ago: import( creates confusion because
it looks like a function but isn't a function.
DD: This is a syntactic form that's function-like. super is a prominent one. Also, you can do (x => import(x))
RW: That's a good precedent to cite for this (w/r to "it looks like a function, but isn't actually a function object")
Promise.all(["a", "b"].map(name => import(name)).then(() => ...)
BF: To clarify, even in Node, it would return a Promise
DD: Even if Node wants require to be synchronous, asynchronous background loading of modules is useful, e.g. lazily loading things from JSDOM.
MRS: In Node, we'd probably still do sync I/O and just return a Promise
BF: Can still use require to basically this. The advantage to load the
dep graph in a non-blocking way was explored via require.async() (pfft.
whoops)
AWB: I was initially skeptical but like this proposal. Good for scripts, including for using built-in modules from scripts. Though you may want built-in modules to resolve synchronously.
AK: But it may take a long time to load the built-in module and want it to be asynchronous
AWB: Also, we could add the import statement to scripts
CP: Do you plan to allow require within module source text in Node?
BF: Probably we'll have some way to get ahold of require, but we'd really encourage people to use import.
BB: Maybe you'd import require from a built-in module.
AK: Why is there a new hook for HostFetchImportedModule?
DE: Isn't this like adding something to [[RequestedModules]] dynamically?
Conclusion/Resolution
- Stage 1
- Becomes Stage 2 at the end of the day tomorrow, noting that we are seeking feedback from DH and YK which may affect this.
- Reviewers
- Caridy Patiño
- Allen Wirfs-Brock
- James Snell
Revisit System.global => global
JHD: Reviewers and editor have signed off on the spec text.
- Willing to make it
enumerable: truepending implementor feedback
JHD: Hope to have as many browser implementations before Stage 4
Conclusion/Resolution
- Stage 3
11.2.b Intl.Segmenter
(Daniel Ehrenberg)
DE: Unicode defines breaking properties: grapheme, word, line, sentence breaks.

- Want to remove
Intl.v8BreakIterator(sorry about that!)

// Create a segmenter in your locale
let segmenter = Intl.Segmenter("fr", {type: "word"});
// Get an iterator over a string
let segmentIterator = segmenter.segment("Ceci n'est pas une pipe");
// Iterate over it!
for (let {index, breakType} of segmentIterator) {
console.log(`index: ${index} breakType: ${breakType}`);
break;
}
Short-cut accelerated API:
let segmentIterator = segmenter.segment(
"Ceci n'est pas une pipe");
// next() returning undefined
segmentIterator.advance();
// index of current break result
segmentIterator.index();
// breakType of current break result
segmentIterator.breakType();
WH: Is the iterator the only API you're proposing? If you just wanted to turn a string into an array of words in that string, is there a quick way of doing that?
DE: For now just planning on providing the lower-level API. Things like that can be built on top of it.
JSL: Only works if you have full ICU (Intl.v8BreakIterator), ideal if
this can be made to work with small ICU
WH: What does this do for indices at which there are no breaks? Does it have a concept of "no break", or does it just omit them from the iterator output?
DE: It omits them.
WH:
Hello, "world"! \n\n
Where do the word breaks go here, and are the decisions configurable?
DE: Explained in unicode.org/reports/tr29 (UAX29)
WH: Might be nice to also include a segmenter that indicates character boundaries; i.e., everywhere except between UTF16 surrogate pairs.
AWB: Intl standard-optional, not standard-mandatory
- Is this functionality something that you want tied to the optionality?
BT: grapheme doesn't require a lot of data
DE: The advice is: callout to ICU or you'll do it wrong
BT: is Segmenter based on UAX29?
DE: Both UAX29 and UAX14
Mixed discussion about ICU data, etc. Dan answers all questions.
SYG: cannot reverse a string and get same breaks
WH: Reversing doesn't make a difference. In either the forward or reverse case you may need arbitrarily long lookahead and lookbehind to determine the breaks. For example, there are emoji grapheme breaking rules that state that if you have an even number of characters preceding your position then you have a break, but if you have an odd number then you don't. So you need to consider the input string as a whole.
WH: UAX29 lists lots of configuration sub-options for different kinds of breaking choices. Is it your intent to support those?
DE: Yes.
JSL: ideal to get rid of prefixed.
Conclusion/Resolution
- Stage 1
Sept 29 2016 Meeting Notes
Brian Terlson (BT), Michael Ficarra (MF), Jordan Harband (JHD), Waldemar Horwat (WH), Tim Disney (TD), Michael Saboff (MS), Eric Faust (FST), Chip Morningstar (CM), Daniel Ehrenberg (DE), Leo Balter (LB), Yehuda Katz (YK), Jafar Husain (JH), Domenic Denicola (DD), Rick Waldron (RW), John Buchanan (JB), Kevin Gibbons (KG), Peter Jensen (PJ), Tom Care (TC), Dave Herman (DH), Bradley Farias (BF), Dean Tribble (DT), Jeff Morrison (JM), Sebastian Markbåge (SM), Saam Barati (SB), Kris Gray (KGY), John-David Dalton (JDD), Daniel Rosenwasser (DRR), Jean-Francis Paradis (JFP), Sathya Gunasekasan (SGN), Juan Dopazo (JDO), Bert Belder (BBR), Shu-yu Guo (SYG), Eric Ferraiuolo (EF), Caridy Patiño (CP), Allen Wirfs-Brock (AWB), Jacob Groundwater (JGR), Adam Klein (AK), Istvan Sebestyen (IST), Tom Van Cutsem (TVC), Istvan Sebestyen (partly, via Hangouts), Claude Pache (CP), James Kyle
Istvan Sebestyen: The audio is very bad, unfortunately. ... Maybe I better write.... Regarding the 2017 European meeting tell me when should it be. In March it would probably be cheaper. Also still skiing would be possible after or before the meeting if someone cares for that. May will be more expensive. Meeting place suggestion: Montreux - Royal Plaza Hotel.
Something else: Status of Fast Track to ISO/IEC: The ECMA-414 needs a 2nd Edition before we can move ahead. I think this has been discussed already. On ECMA-404 JSON Fast track, the DIS voting is going on, and will end in Decmber (I think December 8, 2016). Nothing to be done right now.
No European meeting in 2017, but East coast meeting instead. Host: we find it out....later. The new idea is, just to have every 2 years European meeting. We should rather have also East Coust meetings. Possible hosts: Google, Bocoup....
In order not to spend too much time in the face to face meetings please address any issues on GitHub where the Secretariats issues are discussed.
Have a good continuation of the meeting.
Need new Chairman. Please consider. This is so not true. We need to look how the Chair question develops. Currently not clear.
11.iv.c Consolidating Proxy integrity checks,
(Tom Van Cutsem, Claude Pache)
AWB: Background: There was a missing Proxy check, and in response, Tom and Claude have come up with a fix and a nice formalism. This is of interest to a few people, so let's not all talk about this for an hour.
- Propose delegating Tom, Mark and Claude to work on this
- Present summary
MM: I am confident that
YK: Q...
- An example of the bug?
- What is the fix?
- Any incompatible changes?
TVC: tc39/ecma262#666 . Proxies are designed to not circumvent invariants of objects, namely non-configurability and non-extensibility. The Proxy will check that the handler returns a value consistent with the target.
-
If you have a non-configurable property on the target, and the Proxy says it's configurable, it's a violation.
-
If <invariant>
Claude went through and found a few missing invariant checks based on writing these things out exhaustively:
- A proxy is allowed to say a prop is non config, non write, even if only marked non config
Bug shown: tc39/ecma262#666
A client of the object can assume x always 2 (non-writable, non-configurable), call defineProp on value, set to 3. The proxy was allowed to change the meta property settings:
var target = Object.seal({x: 2})
var proxy = new Proxy(target, {
getOwnPropertyDescriptor(o, p) {
var desc = Reflect.getOwnPropertyDescriptor(o, p)
if (desc && 'writable' in desc)
desc.writable = false
return desc
}
})
Object.getOwnPropertyDescriptor(proxy, 'x') // !!! should throw
// { value: 2, configurable: false, writable: false }
Object.defineProperty(proxy, 'x', { value: 3 })
Object.getOwnPropertyDescriptor(proxy, 'x') // { value: 3 }
MM: Are the other two bugs analogous?
TVC: The second is the same (the DefineProperty case). The third is a little different--[[Delete]] for a Proxy of a non-extensible object, which will return true without deleting it from the target. You could then see some kind of adding properties on a non-extensible object, putting them back.
var target = Object.preventExtensions({ x: 1 })
var proxy = new Proxy(target, {
deleteProperty() { return true }
})
Object.isExtensible(proxy) // false
delete proxy.x // true !!! should throw
proxy.hasOwnProperty('x') // true
MM: If the object is non-extensible, a deletion of a property should succeed if the trap deletes the property from the target, right?
TVC: Yes
MM: Consensus?
- As a bug fix that should happen
- Work with implementors to avoid problems
- Identify further constraints
DE: This should be doable in V8
YK: Should this break any users?
MM: I don't know, but it shouldn't break my patterns--all of my code which uses Proxies is for security and is insecure due to these violated invariants, and would benefit from these changes.
YK: Only way this affects a proxy is author is concerned with extensibility, specifically configurability and writability. If you're trying to virtualize the invariants, then broken.
Agree that's probably "malware"
DE: I'd expect that non-security-related code using Proxies is unlikely to care much about extensibility and configurability, so it is similarly unlikely to break.
AWB: is there a PR with fixes?
TVC: Yes.
RW: Confirm? PR for implementation or spec?
AWB: Spec.
Yes
DE: Tests for Test262?
- Will help TVC proceed, getting oriented in test262.
AWB: Claude's methodology for describing invariants is something we could incorporate into the spec, but this is more than the bug fix.
MM: likely a separate effort, but completely agree.
DD: Sounds like a good non-normative change that could be done in collaboration with the editor in a PR, appendix, etc.
Conclusion/Resolution
- Two parts for TVC/CP as next steps:
- Treat PR 666 as spec bug fix, which needs test262 tests to land
- Treat Claude's new formalism as new content via PR to incorporate into spec
10.ii.b Rest/Spread Properties
(Sebastian Markbage)
sebmarkbage.github.io/ecmascript-rest-spread
SM: Related new proposal: getters and setters are expected to work more like fields than methods. However, they are defined on the prototype, as well as non-enumerable. Confusing when trying to deprecate a field, make it lazy, etc. However, own enumerable checks required for analogy to existing patterns.
// getters are non-own
class Foo {
bar = 123;
}
let data = {
...new Foo()
}
data.bar // 123
Options:
- Leave things as is, and use Object.defineProperty to make own
getters/setters
- New syntax for own getters/setters
- Breaking: Change getters/setters in class syntax to be own properties
(murmurs from room: No chance!)
- New field flag in property descriptors
Generally held rejection of changing getters/setters to be own properties
RW: Implementors have rejected new fields in property descriptors many times before
DH: Objects as a dictionary are an anti-pattern, but rest/spread are like FP OO record operations.
SM: I'd like to figure out how to solve this issue
WH: The field flag (from Plausible Solutions slide) would be per-property or per-object?
SM: Proposal can be structured either way
SM: (did he say going up the prototype chain?)
JHD: If it's not restricted to own properties, wouldn't it get the getters all the way up the prototype chain? We don't have anything in the language (post-Reflect.enumerate) which goes up the prototype chain like that.
YK: This sort of issue comes up if you evolve code between bare objects and classes. Getters don't interact well with adding new things in a backwards-compatible way as they don't have enumerability.
DD: Some getters are fields, treat as such; some aren't and shouldn't be treated as such. (Examples: vector.length; person.fullName) don't think we should have generic mechanism to apply to all getters/setters
- The idea "what are fields of an object"?
- What are the iterated values of an object?
- Should there be a protocol to determine keys and values for spread?
WH: We have a protocol: enumerable, but it doesn't quite match the concept of a field.
DD: need a more general protocol where you can run arbitrary code
MM: clarify: the details of no-change position?
- Things considered a field: enumerable own, a data, an accessor?
JHD: Exactly as object.assign works now
MM: Adding a field to prop descriptors is an extremely heavy weight thing and needs an earth shattering reason to consider. "world needs to end" importance. This is not that.
- Most compelling precedent for "no change": JSON and Object.assign. We got it right when we said "enumerable own"
JM: Did you discuss making getters not own and making enumerable spread--
SM: I don't think that's a good idea
AWB: I don't think there's an easy fix here. Objects have two roles:
-
as tuples (value oriented abstraction, named values)
-
instances of things you can think of as some kind of classes (behavioral)
-
getters are mostly on behavorial side; you could put a getter on an instance, but atypical
Normal usage is one of those two worlds. Proposal: Remove the own restriction
FST: Some getters you want to be shared, some not.
- Augment definition syntax?
DD: Decorators will address this
YK: Enumerable own is important because
- in ES3, common to override prototype properties
- ES3 ad-hoc mixin object chains were note commonly used as record abstractions; for-in was used in these patterns, hence enumerability
...That has changed.
- Now, class patterns increasingly used to express record abstractions
- important that the cowpath does not break
- enumerable-own, historically a hack
- important that hack doesn't break
- in this case, that hack predates getters (RW: not sure this is true)
MM: Given this precedent, anything nearby that can benefit is an argument for doing something analogous
YK: To clarify, from jquery's perspective, this stuff is more of a feature for dictionaries, with arbitrary keys. The mismatch is that ... wants to feel like a record feature.
MM: (@YK) can you write a decorator to make own?
YK: Anytime you make a prototype thing, you add cost.
MM: cases wher eyou want g/s to show up as own property: make it own. The overhead of per-instance g/s to have it be own, seems like fair cost
FST: I might disagree, depending how common the pattern is. There is real memory overhead.
AWB: proposing to possibly eliminate own restriction, but only for inherited enumerable getters
Rest/spread would grab both:
- own properties
- inherited, enumerable accessor properties that have a
get
AK: Wouldn't work well with the DOM; everything in WebIDL is an enumerable getter.
SM: Syntax?
AWB: No, use Object.defineProperty or a decorator
MM: Theory that there is no overhead for the pattern of using own getters — can reuse same getter function objects on multiple instances
FST: It seems like there would be some overhead still
- SM proposal stay at no change
- given sharing of g/s is minimal enough to use as a way to work around book keeping
JHD: This feature is syntax for a pattern that's been used for years across code bases: Object.assign. Because of this weight, we should strongly consider the no change option. APIs/ecosystem patterns haven't proven out in the ecosystem before codifying it in the language.
DD: We should make sure that new syntax solves something new and important. If we're not serving the record programming model, we shouldn't bother with new syntax and just go back to using Object.assign.
SM: I agree that the record use case is a different mental model than the dictionary use case. But we do have a solution, which is for library authors to define own getters.
SM: So, I'd like to go to Stage 3 with the current "no change" proposal.
DD: Suggestion: We could add a protocol later, and make this feature retroactively tie into that.
YK: the reason this is coming up is that if we ship this with the specced semantics, we close the door on something like Allen's proposal of changing to enumerable not-own. I would like to know whether per-instance getters introduce new performance problems.
Implementers: There will be measurable overhead, but it might not be all that expensive
DH: This proposal always creates Object instances; for record programming, we may want to, in the future, add a protocol for making instances of other superclasses. Not blocking, but good to look into in the future.
SM: We could also do that for Arrays.
Conclusion/Resolution
- Stage 3, currently with the "no change" option from the Plausible Solutions slide
- We could add a new feature in the future that overrides the default behavior, but that does not block this in any way
10.v.b Date.UTC when called with one argument
(Brian Terlson)
BT: Date.UTC with one argument
Last meeting:
- Date.UTC() => nan
- Date.UTC(_) => Implementation-defined; Chakra had different behavior
AWB: The only two reasonable results would be to give the first instant of the year (Chakra behavior) or NaN (other implementations)
Proposing: defaulting all subsequent arguments to 0 when called with only one argument
MM: What's the bug we'd be fixing here by returning an error?
AWB: Trying to parallel Date constructor (historic)
BT: Let's go for the functionality and make it work with just a year
Conclusion/Resolution
- Date.UTC(year) defaults all the other parameters to 1 or 0 (i.e. returns 00:00:00 on January 1st of that year)
12.i.a Remove arguments.caller
BT: The poisoning is pointless now, we won, let's remove it
Conclusion/Resolution
- Consensus!
Revisit ECMA414, 2nd Edition
AWB: (recapping ECMA414 2nd Edition)
Motion to approve ECMA414, 2nd Edition
(Requires formal vote)
Bocoup: Yes jQuery: yes Apple: Yes Microsoft: Yes PayPal: Yes Mozilla: Yes Google: Yes Yahoo: Yes Salesforce: Yes Shape Security: Yes Facebook: Yes Godaddy: Yes IBM: Yes Netflix: Yes Tilde: Yes Airbnb: Yes
Next: ok to delegate TR104 updating to AWB and LB?
YES
Conclusion/Resolution
- ECMA414, 2nd Edition approved, send to Ecma/GA
- TR104 updates to be forwarded to Ecma/GA
11.iv.b Cancelable Promises
(Domenic Denicola)
tc39/proposal-cancelable-promises
Status: issues.
DD: I don't like mics
MS: What's wrong with Mikes?
DD: The feedback made it in the new spec:
- had await.cancelToken idea. now fully specified. Allows the 'race' convenience semantics
- method: Promise.withCancelToken as a convenience method for adapting old APIs (changed from Promise.cancelable => Promise.withCancelToken) -- was
this the same thing?
tc39/proposal-cancelable-promises/blob/master/Cancel Tokens.md
- try/else is the new try/catch which doesn't catch cancellations. For future compatibility with catch guards, we can't use a new contextual keyword
tc39/proposal-cancelable-promises/blob/master/Why Else.md
WH: explain issues with catch guard?
DD:
try {
f();
} except (e match SyntaxError) {
b();
}
except(e);
{
c();
}
WH: Still ambiguous with else and unbraced if, multi-else changes
existing behaviour after you introduce the one-else variant
DD: This is the same as the existing unbraced if/else ambiguity, and
doesn't extend it further.
KG: An if whose body is a try followed by an else?
DD: Cannot do that
MM: Problem: going into a similar area of then, but with different
meaning? When you see then/else...
- Believe
then/elseis damaging
AWB: These are all failure conditions? Why not fail?
DD: Ambiguity with match
YK: else makes sense semantically
DD: Last time, no stage 2 because
- want to use cancel tokens as a general cancellation system, including
Observables, which otherwise have an
unsubscribemethod andclosedproperty - A polyfill implementation exposed issues
tc39/proposal-cancelable-promises#57
Propagation is asynchronous, but needs to be synchronous for Observables.
Proposed way forward: CancelToken.race has their arguments refer to their return value, so they can push the results out, rather than waiting for the Promise.
When using CancelTokens more manually than race: - Naive solution: subscribe, and then check and bail out based on flag. May be inefficient - Add unsubscribe method to Promises-- .unThen()
JHN: Tradeoff between complexity of CancelTokens and usability in more things such as Observables
YK: Cancelation tokens have large scope than Promise?
DD: Yes: streams, observables, promises (and so on)
MM: Notification only delivered as then callbacks are, in a later turn?
BBR: So the cancelation is more an "intent"?
.reasonmuch be synchronously updated- Complexity comes from dependency between Observables and Cancellation
MM: the requirement that the notification be async isn't fatal to your design goals?
No.
DT: motivation for the token specified by promise underneath?
DD: Public api is a .promise getter
DT: Any reason why should be? or .then on a cancel token?
DD: Then creating an ad hoc api for tokens? No, we have something for that: Promises
DE: Some in Web standards are considering ad-hoc thenables as more ergonomic
DD: This is bad, and just for web-compat reasons
DT: Is it the right thing to do unThen?
JH: Avoiding closures is important for some userspace Observables libraries
JHD: What happens to the Promise when you unThen them?
MM: Maybe cancellable registration should not be based on .then? done
does not have an output Promise
DD: No, don't want new unsubscription type.
JH: Lots of paths seem to end up back at this
MM: Could we make this work, if it's simple?
DD: It'd be bad to add two things
AK: Wouldn't unThen be another way to unsubscribe (aside from CancelTokens)?
DD: Yes, we do have this circular dependency
MM: .done()?
DD: That has other problems, e.g., what if you throw?
WH: else and except have the same issue: can have an else in an if, try, else, else
WH: The current proposal claims that else works better than except
because supposedly else allows for future extensibility to multiple
else clauses. This is incorrect.
WH: The current proposal allows at most one else-type clause after a try.
That works. It works regardless of whether the keyword is else or
except.
However, the proposal claims that else is better because it then allows
for a future v2 proposal to introduce multiple else-type clauses after a
try. That's not the case because v2 would incompatibly change the meaning of
if (...)
try
{...}
else (e)
{...}
else (e)
{...}
DD: Let's follow up on GitHub with details
Conclusion/Resolution
- Not proposed for Stage 2 at this point; too many unsolved problems.
11.iii.c Observables
(Jafar Husain)
docs.google.com/presentation/d/18KkpDm0Z-lGnUFxcK_ZJwSKCSalnBqjhGN8W--PyT88/edit#slide=id.p
JH: Previously, .subscribe() would get set up using a .start() method
which starts delivering values with the Observable once it's already set up.
Having the consumer pass in the CancelToken is better because the consumer doesn't need to wait for the producer to wait to deliver the subscription.
DT/MM: Ability to observe the cancelation
JH:
- not designed to be dist system safe, just a primitive to design other useful classes on (EventTarget, EventEmitter)
- Schedules some things synchronously when it makes sense, just like EventTarget, though other times things are asynchronous ("releasing zalgo"). There's no real benefit to waiting asynchronously for a map, etc.
- observable
// Calling
function zalgo(callback) {
if (someConditionIsSatifiedNow) {
callback();
} else {
doTheTask();
process.nextTick(_ => callback());
}
}
zalgo(_ => console.log("not clear if this will be invoked asynchronously or
synchronously"));
DD: Observables, Promises and CancelTokens compose well--Observables can have APIs that return Promises, as I presented at TPAC in this example
DE: Is there a code sample which takes advantage of the synchronicity of observables here?
JH: The performance benefits implicitly come up in this code
DE: Well, if it were OK, then Promises could also be made faster by "releasing Zalgo" and not delegating everything to the microtask queue
JH: Observables encourage a more functional programming style, and Promises encourage a more imperative programming style, so it's OK to be synchronous to observables.
DD: if Observables are going to cover EventTarget, then must be sync
MM: Do you need anything else from cancel tokens for Observables?
JH: We only need the 'race' change to make the cancellations synchronous
DD: Then I don't need unThen and could go to Stage 2 for CancelTokens!
MM: Would this paint us into a corner, if we want to add unThen later?
(Discussion about polyfills, staging, getting people to use it, etc)
Conclusion/Resolution
- Not advancing, pushing the pause button for now
11.ii.d Sigil swap: decorators <-> private fields
(Jordan Harband)
JHD: More sense to...
Propose:
- @ for private
-
for decorator
BBR: Node.js looks for # on first line. A decorator could be at top
level, but private could not
(Should key on #! anyway)
# IdentifierName
FST: All other languages use @ for annotation/decorator?
Generally, this is not the only cultural motivation for design decisions.
DE: As private field champion, I am neutral.
Kevin is strongly in favor of the sigil swap.
@is a very intuitive way to signify private state.
DRR: Unclear why @ for private is more preferrable to #?
RW: Allen's @names effectively reserved this years ago, because we always
wanted to revisit. Evolved into privates today
...Moving to discussion about code that exists
- Angular
- TypeScript
JHD: There will be code that requires no modification and code that requires some.
AWB: There is no code that doesn't go through SOME kind of transpiler. Its not like web code that cannot be broken. Transpilers can handle the code generation.
RW: (example where we changed exponentiation operator syntax and it was just a version bump)
JHD: codemods could be used to swap the sigils; the community is new to this
JK: Decorators are not part of a preset, they are part of a legacy-labeled third party preset. We have explicitly told Babel users that they will need to install something new when this comes up. We will not actually have to do a a major version change when this comes up. Specifically for changes that might occur
YK: Our changes for Stage 2 were intended to allow just decorator authors to have to upgrade, and not decorator users. These things can be considered stable. Downstream consumers will not break
JHD: Plugin option? Legacy sigil or not?
BT: Angular and TypeScript add that option? It's not a solution.
JK/YK: (discussion re: paths forward)
Updrade as they write, without change.
DRR: Code that wont go through transition phase. Concerns about docs and blogs with old syntax.
RW: We have lived through many things changing in the ES6 process, for example generator expressions being removed
JHD: And don't you have compat issues between TypeScript and CommonJS and Babel?
DRR: Yes, but that's really painful and you want to avoid it
JHD: If you're using a non-standard syntax, you shouldn't have expectations that it shouldn't change.
YK: Generally, we should be able to make changes, but we should also be able to weigh existing users vs rational arguments
BF: JSDoc, etc use the @sigil to document something about the following declaration. If it also represents private state, I would find it confusing personally.
JHD: But doc comments are entirely different from runtime decorator semantics
RW: JSDoc is outside of our committee; we can't let them set the rules
DRR: But there is motivation to look at what exists in programming culture
DT: It'd actually be great to have a different syntax separating the comment and code syntaxes
FST: Confusion about what appears in comments vs what appears in code?
No. But some think it matters what exists in the ecosystem.
AWB: As a sigil for identifying special kinds of variables, like private state, @ is much more common in terms of number of languages. # as hashtag is a cultural reference, but it's completely separate from @--each of these sigils have context where they evoke something in people.
JHD: This will be there for a long time; appeal to the long tail of future programmers, where "hash tag" is something of a "categorization", decorators deal with a "category" of things.
DH: Early adopters through transpilers give us very strong feedback and are great allies in our committee who it is important to value. This raises the bar for backwards-incompatible changes.
JHD: Next versions of Babel, TypeScript could easily produce a code-mod to upgrade.
DE: decorators will have to be updated between stage 1 and stage 2, but to represent the Angular team, their interest is that users of decorators don't have to change, with the expectation that most programs will not implement their own decorators but rather use decorators from the framework, which will be the only one who has to do the transition. It's not hard to imagine that it will be difficult for some build environments to update themselves.
Discussion/debate of detriment of the swap. Claim: Users call all sorts of different things '.js' and don't document which build flags they need.
JK: If Babel or other transpilers are blocking TC39 from work that it wants to do, then that's not what we're going for, and we should change the ecosystem on our end.
AWB: If we can't make changes like this, it calls the stage process into question.
YK: We can make this change, the question is: should we make this change?
KG: Rough estimate of the number of people who would have to do non-trivial change?
BT: Tens of thousands?
KG: Compared to tens of millions later?
DH: Fails to account for the trust relationship
BT: On the one hand: real cost for developers today.
AWB/JHD: Real cost for teaching for the next 50 years
WH: # as Twitter hash-tag is not going to be around for the next 50 years
JHD: multiple networks have adopted the syntax, so i think it will mean "hashtag" for far longer than that
RW: We're setting a bad precedent in allowing Babel and TypeScript code to determine the course of ES evolution
DRR: This is not the intention of TypeScript,
Conclusion/Resolution
- No sigil swap at this time; seems difficult to achieve consensus on such a swap in the future.
- Could revisit later, but it would require a strong argument beyond this.
- Features that are not stabilized are subject to change in general and should not be expected to be stable at all, especially if they are at Stage
11.iii.b Async Iteration
(Domenic Denicola)
DD: I took this over from Kevin Smith and resolved a number of issues in PRs. Main issue: where does unwrapping happen?
DD: Conclusion: The contract is for .next() to return a Promise of an IterationResult, not a Promise of an IterationResult of a Promise, by:
- The @@asyncIterator's .next() .value is not a Promise
- So, for example, %IteratorPrototype%[Symbol.asyncIterator] will do the unwrapping
- Previously, yield Promise.resolve(1) from within an async iterator, creates the badly behaved iterator
- Now, the async generator object's .next() method does the unwrapping for you. Observable case:
var asyncGen = async function* () {
yield delay(100);
console.log(1);
}
Then the print would happen right after asyncGen.next(), rather than waiting for delay to end, but the Promise that next returns would only be fulfilled when the delay is done.
MM: Harm in having the for await loop do the double await?
- I know the benefit, but what is the harm?
DE: From performance perspective: becomes a triple await. Expect most to use built in either async iterator or an async generator, both of which will follow the contract anyway.
DD: Sync iterators have a contract which is not enforced either
MM: If write something that acts like a badly behaved iterator, what ways can I "surprise" your for loop
DD: You could keep returning values after you return a done: true
DE: fail to clean up in your return method
YK: Hard to write correct, manual version of this.
MM: other than performance argument, don't see another correctness downside?
YK: The more you clean up after people who get manually written iterators wrong, the more likely they are to get them wrong and not notice.
MM: Good point.
DE: small changes after my review, havent looked at them yet.
BT: Nothing missing, no major concerns
Conclusion/Resolution
- Stage 3
11.ii.c Set, Map, WeakSet, and WeakMap: of and from methods
(Leo Balter)
leobalter/proposal-setmap-offrom
LB: Adding of and from to Map, Set, WeakMap & WeakSet
- Provide collection creation symmetry with Array
MM: What value does it add over just constructor
AWB: The constructor for these all take a single argument: iterable. if you what you want to do is create, eg. a singleton set and want to be able to accommodate any value passed to you, eg. a string to set. Only safe way is to put it into square brackets.
DD: Versus the constructor, I think of saves square brackets, and from
is completely redundant.
AWB: it's not about saving characters, it's about following a convention that's consistent with Arrays.
DE: TypedArrays have of and from
AWB: And we added that to make a general convention
YK: We have to teach people something about the idiom of the constructor. Given that we already have new Set, it would seem to make sense to use here.
FST: What is the cost of adding consistent APIs across all collection classes?
DD: Not deprecating the constructor
FST: don't need to deprecate
KG: insane not to provide a way to make the collection without forcing the brackets
AK: Other evidence from the wild about demand? Is there a widely used library for this?
LB: When working on test262 tests, we needed many tests for the constructor taking iterables of iterables.
JH: Any polymorphism involved?
AWB: Subclassing or .call'ing this on other constructors would encounter
this issue, yes; you'd need to call .add() or something.
- Inconsistencies between which collection classes have this API and which do not
MM: A clean API surface is not necessarily a larger API surface.
FST: Without these, I would think that this would result in user "wat"
YK: A lot of this could be avoided by giving better error messages in our implementations.
DH: I don't like having brackets, but I also want to have new, which is nice, which overrides it.
AWB: Our API taking an iterable for the constructors is actually a good choice for a clean, general constructor.
JH: of and from can be used to create polymorphic apis
[More raucous debate]
MM: Don't want this in the language, but don't object to stage 1.
Conclusion/Resolution
- Stage 1
Arrow Generator Revisit
(Domenic Denicola for Brendan Eich)
?
let f = () => * {}
DH: Argument against: We're probably not going to make class *, so why do
need to make arrow *?
- We don't say that any two things that have syntax have to have matching syntax
WH: What would class * even mean?
widest class of strong idioms to support?
DD: Need to go back and get more evidence.
Conclusion/Resolution
- Stage 1
- Please look into use cases
- Discuss syntax details and analogies further.
11.iv.c Built-in Modules - Let's Pick a Syntax
(Brian Terlson)
import DateTime from "_?_DateTime";
BT: There has been desire for inclusion of built-in modules since dawn of modules. Safe place to introduce new things.
- Working with moment.js to fix date things. ~10 new types.
- Things like DateTime
BT: Asking... do we want built-in modules?
DD: We should not move to world where features added after 2018 are in modules. Leave modules to user space.
DH: Strong point, not specifically in agreement.
FST: We could make duplicate modules for existing built-in things, and maybe eventually we'll take things out of the global namespace in 10 years
- Long term cleanup? (Probably not)
DH: One view of the future is that we wont have an enormous library, expanded without bound. Maybe individual ecosystems will introduce standard built-ins
AWB: explicitly in the charter to explore standard libraries
DH: Limit to how fast and how much
MM: Very strongly in favor of built-in modules. Issues to be aware of and address:
- global namespaces pollution way past breaking point
- any built-in module needs:
- Polyfilling must be "what becomes" the standard set of modules
- Primordials all have the property that you can freeze and make immutable
- Need polyfills for built-in modules to be able to do this
BT: Polyfills are just the start--testing hooks, etc
DRR: Feature testing--you can use import() and see what kind of Promise you got out of that?
DH: must have a registry API to reflect on modules
WH: Underscoring polyfillability requirement
WH: Also, you'd fall off a cliff when trying to use one of these built-ins from a traditional, non-module, imperative script. You'd need to convert everything for modules, since import() is asynchronous and harder to use from scripts
JHD: You need to patch it in a polyfill before anyone can use it, not necessarily synchronously
WH: And you'd have to await before anyone can use the thing from an async module load. It would be annoying if, for example, Date or Math had been modules that worked that way.
YK: It's useful to be able to see what's already present, as you can with properties of the global object
DT: We need to do this in a structured way with respect to naming, so people don't fall on landmines, to avoid colliding with user code.
CP: Some Node users like to have things in modules, even when just wrapping existing globals.
DD: What is the motivation?
BBR: This is a matter of consistency. It's fine if TC39 adds some things to the global object, so will it get "full"? It would be nice to have a system way of loading libraries.
JHD: Polyfillability is important, and it leads to the same collision issue with the same bad global namespace.
DD:
- Fundamental tension between polyfilling/collisions vs reserving/no-polyfills.
- Anyway, will we do a bad job organizing the new namespace (of things like whether Foo goes into module A or module B), and regret it, so no point in changing anything.
- modules can be loaded asynchronously
- good example: SIMD
- globals cannot
AK: As to breaking users by adding things to the global object: I didn't remember Set breaking anything, anyway. And modules for user code make this nicer, with the lexical tier making it even nicer and less risk of an overlap. So this does not seem to be a very strong piece of motivation for built-in modules.
BF: We have to do the global/local cache for exactly this reason, for polyfillability, namely punching something out locally so it can be replaced. This is a huge topic.
MM: As a counterpoint to AK, Adding JSON broke Facebook, Facebook changed
MM: They were shipping a stringifier and parser, but not to spec because it pre-dated the proposal
(RW, sidenote: ironic ^^^ considering the conversation earlier)
DE: We had compat issues shipping ES2015 due to polyfills as well.
DH: Introducing a new namespace makes it clear that we are talking about candidate standards, rather than user code.
BBR: Why polyfill?
JHD: Fix browser bugs
AK: Testing, replacement with different functionality
DH: Maybe there should be a way to ask for the builtin thing
MM: For SES, being able to get to the outer original thing would subvert the security model.
JHD: I'd also like to replace things for my polyfills and not give access to the original one
BT: And let's bikeshed on the syntax! "std:..."
DH: Shouldn't it be / to meet the JS ecosystem where they are?
BBR: That would already have a semantic
BT: Another option: import DateTime;
DE: Seems a little confusing with the analog to import "DateTime" doing
something completely differen
Conclusion/Resolution
- Stage 1
- Need to craft a plan in accordance with committee concerns
- Polyfillability, including Mark's concern about ensuring you can disallow access to the original
- Domenic's concerns about bifurcating the world between pre-2019 APIs and post-2019 APIs
- Eric Faust's concerns about polyfills leading to a tension with the possibility of namespace collision

I didn't see them on GitHub or anywhere, so I was just curious if there was a timeline on when they should be up.
Isiah Meadows me at isiahmeadows.com
Looking for web consulting? Or a new website? Send me an email and we can get started. www.isiahmeadows.com

They should be up soon, just need to be reviewed by more people

Typically, the notes are published after a week or two, so that all TC39 members have a chance to review them.
They will appear

just noticed the notes are up now - tc39/tc39-notes/tree/master/es8/2017-09, tc39/tc39-notes/tree/master/es8/2017-09
September 24 2014 Meeting Notes
Brian Terlson (BT), Allen Wirfs-Brock (AWB), John Neumann (JN), Rick Waldron (RW), Eric Ferraiuolo (EF), Jeff Morrison (JM), Jonathan Turner (JT), Sebastian Markbage (SM), Istvan Sebestyen (phone) (IS), Erik Arvidsson (EA), Brendan Eich (BE), Domenic Denicola (DD), Peter Jensen (PJ), Eric Toth (ET), Yehuda Katz (YK), Dave Herman (DH), Brendan Eich (BE), Simon Kaegi (SK), Boris Zbarsky (BZ), Andreas Rossberg (ARB), Caridy Patino (CP), Niko Matsakis (NM), Mark Miller (MM), Matt Miller (MMR), Jaswanth Sreeram (JS)
Object Instantiation Redo
(Allen Wirfs-Brock)
instantiation-reform-sept2014.pdf
AWB: (introducing discussion from last meeting)
AWB: how many people here have read these gists? (hands are raised) OK, about half the people... The others are going to have a hard time.
Slide 1, 2
Introductory
Slide 3
Main Issues
AWB: The design long holding consensus was found to expose uninit instances. If it's an exotic or built-in with some invariant to maintain, instances may be produced that do not uphold the invariant.
Slide 4
Original Idea From Claude Pache
class C extends B { constructor(...args) { /* 1: preliminary code that doesn't contain calls to a super-method */ /* this in TDZ */ /* 2: call to a super-constructor */ super(...whatever); /* this defined */ /* 3: the rest of the code */ } }newwas originally applied to.thisbefore entering the constructor, a TDZ exists until the super callSlide 5
Addtional Idea Presented at Last Meeting
new*token - Value is the "receiver" parameter from [[Construct]] or undefined if [[Call]]Object.create(new*.prototype);new*has been replaced bynew^new^is the "receiver" argument to [[Construct]]. Undefined if called as a function otherwise.new^chosen as alternative tonew*sincenew*doesn't align with other uses of *, and new^ seems more appropriate.Slide 7
new super()Use
new super()rather thansuper()to "invoke superclass" constructornew super()is always a [[Construct]] invocationsuper()is always a [[Call]] invocationDidn’t want to further confuse "called as a constructor" and "called as a function". – <id>() -- always means "called as function" – new <id>() – always means "called as constructor" – Even when <id> is
superSlide 8
this = new super()thisin TDZ until explicitsuper()call. (nownew super())thisnew super().thisthrow ReferenceErrorMM: "Allows" explicit assignment to
this, implies also allowed to callnew super()without assigning tothis?AWB: Yes. Example is
Proxy(new super(), {...traps});Slide 9
this = <expr>thisassignment in a constructor isn't limited tonew super();this = new super(); this = {x;1, y:2}; this = Object.setPrototypeOf([ ], new^.prototype); this = new Proxy(new super(), handler);Slide 10
Works in both class constructors and function constructors
SubArray.__proto__ = Array; SubArray.prototype = Object.create([].prototype); function SubArray(...args) { if (!this^) this = new SubArray(...args); else this = new super(...args); }MM: You can do assignment to
thiswhen called as a function?AWB: No
Slide 11
Default object allocation (Base Classes)
extendsand basic (function) constructors...thisif body does not have an explicitthis =.class Base { constructor(x) { this.x = x; } } function Base(x) { this.x = x; }Slide 12
Unqualified super references
super()means the samething assuper.<method name>()superin constructor needs to means "this constructor's [[Prototype]]", not "[[HomeObject]].prototype.constructor"super()means something completely different in a constructor from what it means in an non-constructor methodf() {return super()};Slide 13
Eliminate unqualified
superreference in non-constructor methodsclass Sub extends Base { foo() { super(); // now a syntax error super.foo(); // must say this instead } }superonly allowed in class constructors and function definitions.superreferences with a property access.Slide 14
Default Value of
thisin derived constructors that don't assign tothisthis = new super(); // super new with no argumentsthis = new super(...arguments); // siper new all argsthis = Object.create(new^.prototype); // oridinary objthisin TDZ at constructor startBE: Implicit object.create with new^ and subclassing a DOM base class, you end up with wrong thing
DD: Error better than not
(Domenic just named
new^"new-hat")AWB: Most preferred is Alternative 4.
Slide 15
The Winner: No Default
thisto pass to implicitnew super()`thisin derived constructor before referencing it.DH: In the constructor of a class that extends, no implicit this? Subclass would have to explicitly do something
AWB: Yes
Question about dead code removal, if
this =is in a dead code pathAWB: Tooling will have to be updated to understand new class semantics.
thisin a function defintion is meaningless, only works in a class bodyMM: Any way to make derived constructor, base class and function rules?
function f() { this = new super() this.x = 1; }MM: What happens is
f()is called as a function?AWB: If it includes
this = new super(): Runtime errorAWB:
this = new super()does a TDZ checkQuestions about multiple
this = ...JM: In terms of dead code, linters, minifiers (any tooling) will have to become aware.
AWB: Yes.
// Throws because class C { constructor() { this = undefined; return 5; } }MM: In the absense of a valid return, what would be the problem of returning the
thisvalue at the end of the constructor, even if the return value is a non-object?BE/AWB: Consistency. This would be new semantics
MM: Sufficiently different, maybe not worth taking a chance on.
BE: I wanted allow return override. Guaranteed to return an object
AWB: If don't explicitly return an object, the
thisvalue is returned.SM: Difference between assigning to
thisand returning an override?AWB: None
YK: No TDZ?
BE: Invoke a function with new, the return is 5, not an error, just returns the original object
MM: comments about refactoring subclass constructor function to class constructor
B.call(this) => this = new super();(break)
Dave Herman and Yehuda Katz present counter proposal
atat.pdf
Slide 1
Introduction
Slide 2
Problem: Can create half baked objects.
Slide 3
(examples of Foo@@create)
Slide 4
Slide 5
Slide 7
Solution: both allocator and constructor get arguments
Slide 8
new C(x, y, z) ? do { let obj = C[Symbol.create](x, y, z); obj[[Construc]](x, y, z); }Slide 9
Slide 10
Object[Symbol.create] = function() { return Object.create(this.prototype); }; Array[Symbol.create] = function(...args) { let a = %CreateArray%(...args); Object.setPrototypeOf(a, this.prototype); return a; };Slide 11
class Stack extends Array { top() { if (this.length === 0) { throw new Error("empty stack"); } return this[this.length - 1]; } } class Substack extends Stack { meep() { return "moop"; } }Slide 12
let PointType = new StructType({ x: uint32, y: uint32 }); let ColorPointType = new StructType({ x: uint32, y: uint32, color: string });Slide 13, 14
TODO: Copy slide
Slide 15
MM: Difference between the proposals:
BE/AWB/YK/DH: Agree.
BE: Clarify: this pertains to cases where you have split initialization and allocation, such as exotic objects, built-ins.
Discussion re: do not want to expose uninitialized stuff.
DH: issues with previous proposal, aka "new-hat"
new^itself is not good enough to deliver to community.thisappear "mutable" (disagreements)thisAWB: how does #5 differ from current? It's the same.
DH: Any reason why it can't call the construct behavior?
AWB: Construct allocates
DH: Not in this proposal
AWB: Haven't addressed what happens in constructor?
DH: (goes back to slide 8)
need more here... AWB: Are you proposing that all initialization and allocation happen in @@create?
DH: no.
MM: When D inherits from B and you
new Derived()that construct trap of Derived gets called. When Derived constructor callssuper()does it invoke Base's call trap or construct trap?DH: Need a way to distinguish new and call, but super or direct?
YK/BE: have to write another
ifif you want to define subclassable classesDD: overriding the allocator is not part of creating a robust super class
YK: argues otherwise.
DD: enabling overriding the allocator of the subclass hasn't been a goal
BZ: in user code, needed in DOM
...continue.
DH: (explaning future friendly-ness of distinguished initialization and allocation)
Slide 16, 17
AWB: This is speculation of new forms?
YK: For illustration only. Speculate that you will have to build a constructor that defines all aspects of allocation and initialization, forced to figure out how the condition (or whatever userland pattern is)
DH: These speculated forms only illustrate goals.
MM: Options?
3 => NO.
BZ: Want to see how these prevent uninitialized instances
AWB: (restating goals)
DH: Can prevent uninitialized instances from being observed with either proposal
RW: For exotic, built-ins and DOM, @@create produces the fully baked instance and constructor is just a no-op. For user code, that's uncommon. ...
BZ: I am trying to understand how you can guarantee initialization without exposing half-baked objects
DH: The answer is that you move the strict invariant initialization into
@@create. To avoid repetition, you use trusted functions that are allowed access to partially initialized objects and encapsulation, and you only pass thethisvalue from@@createto those trusted functions.DH:
MM: Base class, derived class. The Derived clas is a client of the base class, and it's the responsibility of the Base class. It's often the case of the base class locking down property and that's OK.
BZ: Want to see some class that uses "magic".
BZ: Does ColorPointType get to see an uninitialized PointType instance?
RW: No, because it overrode the one on Point
BZ: Wait so where does the initialization of ColorPointType and so forth take place?
DH: That's how struct types are defined.
RW: What about the examples we worked through last night.
YK: I think what's getting lost is that the normal way for people to use this is to ignore @@create.
BZ: The normal way is fine, I'm not worried about that.
YK: To be clear, what you're saying is fine, but I think it's important for everyone else in the room to know that the normal mode of operation has not changed.
AW: You're right but they also won't pass new^?
YK: But they will have created a non-subclassable object
ARB: I have a question. In the other design, there was a discussion about implicit calls to the superconstructor and whether we should pass the arguments. Both Marc and I made the strong argument that this was not a good idea. As far as I can see, it is doing the exact same thing, but even in a weirder sense, because you're passing the arguments through to the allocator even.
DH: That's true. Allocator signatures have to track constructor signatures. This means that if you are passing extra arguments that may be ignored --
?: Or used in a completely different way --
DH: right -- it means that you have to override @@create if you want there to be a difference
ARB: isn't that very common? in all cases where derived constructor changes what is passed to the base cosntructor
YK: not my experience at all. I think the common case is that you don't really change the arguments that much or just append arguments -- whcih happens to work ok thanks to JS semantics.
DD: I think what will happen is that people will say constructor is an anti-pattern, use @@create so that you only need to do one.
ARB: I've not used ES6 classes naturally but I find "transform" is the common case by far in other languages
DD: isn't that why you subclass -- to modify constructor?
<lots of people talking over each other>
MM: you have to have each level of @@create mirror the transform that occurs inside the constructor
YK: right
MM: do you have a pattern for that which is less onerous than the new^ pattern?
YK: I think that this will happen sometime but is less bad than the
if (new^)patternAWB: No
YK: I guess we have to discuss whether we agree that people should design for
RW interjects: Here is the whiteboard example:
RW: Follow:
g -> new G() -> (no G[@@create]) -> B[@@create]() // done.If B had no @@create
g -> new G() -> (no G[@@create]) -> (now B[@@create]) -> (no A[@@create]) -> default // doneDH: What Rick is trying to say is that for non-exotic objects, none of this matters
DH: Another way of putting this is that exotic objects are a bifurcation inherent to the space we're in, it's part of JS, and it becomes important to know whether there may be exotic objects involved
RW: Point I'm trying to make is that in the most common case, userland classes, we don't have to do anything different
JM: I can't just stay quiet anymore. I feel like we're overstating how common it is to subclass these kinds of "exotics"/built-ins
DH: I want to double down on this. Your prediction is wrong Domenic because I don't see people deciding that they should use the syntactically onerous pattern instead of just using constructor.
DD: I'm saying that based on Yehuda's argument, where he says to be robust you must be prepared for exotic objects, this design is superior, it doesn't seem like this design helps. Instead you just move things to @@create.
YK: That seems ok to me. To people who want to use exotic object subtyping, we can either say "here are a bunch of tools you can use to create a protocool", or we can tell them "here is something that works fine, but you have to use @@create"
DD: In that case, why constructor at all?
AWB: I'd like to explain why I walked away from this design. Fundamentally BZ's issue is about data-based invariants that must be established as part of the constructor, there will be a tendency to push those things into @@create. Besides being ugly, @@create has other downsides. Here's the real issue -- establishing these invariants, what does it mean? initialized private state. Let's think about the future. That method, the @@create method is a method on the constructor itself. That means to initialize the private state of the instacnce you have a function or method that is not attached to that instance that has ability to reach inside and get private state. So over here in the @@create method, however we might define it in the future, in the @@create method you can't say "this. at foo".
(people talk over each other)
MM: Not a capability leak -- if the @@create method is in the same class, it's fine.
YK: I agree but I think that's something we have to figure out generally for private state.
AWB: I'm saying that the model of putting private state into @@create, a foreign method and not the method of the instance, seems wrong.
DH: Here's the thing. @@create is not given an object to produce.
MM: I am confused about something Rick made. If you create a class G, just writing a constructor that calls super constructor, this is a broken class, because it didn't provide a parallel @@create that provided the same transform.
JM: In case where this is not extending an exotic class, it's ok. In the case of something native, like Date, it becomes important. My overall point is that I think it far less common to subclass Date than to subclass userland/non-native classes.
MM: But it's non-compositional.
DD: What's attractive about this = new super() is that it works regardless of whether it's a exotic class or not. Otherwise you have to know.
JM: I think you're right but we're taking what I perceive as an uncommon case and adding burden to the common case.
DD: People want to subclass Array a lot.
BE: Not common, not common.
JM: Let me avoid word "common" for time being. If we're talking about subclassing an ember view, that is not a builtin. It happens a lot.
DD interjects: But what if ember views want to upgrade to typed objects?
YK: It makes 'magic class' a part of the public API.
DH: Every class has two contracts. Contract to consumer and contract to subclasser. Magicness and exoticness is a thing subtypers have to care about regardless.
AWB: Dave, array is an exotic object. I can create a subclass of array today and not care whether it's an exotic object. So one step further. In ES6 as currently spec'd, I want to create a subclass of array, in the constructor I want to do something extra. I just want to log a message or something. I have to do something. In current ES6 design, I have to say super(), decide what arguments to pass, and do my extra code. But again I didn't have to think about whether Array was exotic not. It's only if I'm doing something that somehow interacts with the exoticness that I have to think about it.
BE: Domenic made a good point. I do think we have to argue about what's common though. Obviously there are piles of code building class hierarchy from plain objects -- but what if we want to go from an emberview to something using typed objects. Does one proposal require more changes than the other?
DD: No
NM: I disagree
...
YK: Answer with Ember subclassing proxies is that it is a semver incompatible change. I worked through this last night and I think it's ok.
DH: It's a drop-in replacement for clients but not subclassers.
YK: In the new proposal, it requires subtypers to type
this = new super(), which they may not have had to do.DD: I really like
this= new super(), it's explicit, it makes more sense to me.BE: But that's not the argument.
YK: I don't think we can call it a semver compatible change.
NM: Extensibility is a factor.
ARB: Generally true, right?
NM: Yes.
MM: I'm confused -- when I bring up the transforms of the arguments, response I got is that subclassing of exotics is relatively rare, which I agree, form of the argument is that it's rare enough that we shouldn't make regular code have to pay a price for the common case. Let's stipulate this is true -- under that argument, than the
if (new^)goes away?BE: But you still need
this = new super, and other changes.YK: But if you remove
if(new^)you're making decision on behalf of others?MM: If we apply the same counterargument, it doesn't need the
if (new^), all it needs more issuper()becomesthis = new super()YK: I think you misunderstood the argument. I'm not saying you always have to write
if (new^). I'm saying that it is SOMETIMES true that you have to do it.MM: I want to split the argument. In world 1, we are saying we don't want to burden normal code with worrying about subclassing builtins. For code that does not subclass builtins, it shouldn't need to worry about possibility that it might get reused as a subclass of a builtin. We should not need to pay the price.
MM: In that world, let's compare new^ to the proposal on the board. In new^, in world 1, if this is normal code, super() becomes
this = new super()YK: Yes but what this was saying is that IF YOU ARE subclasing something exotic, you need to do idiomatic things to get plausible results.
MM: But only on the hypothesized small amount of code that needs to subclass builtins.
YK: In the revived @@create, the burden falls on people are subclassing objects, and want to do a transform on the constructor.
BZ: And people who don't know if they want to subclass an exotic.
BE: I think they are lost anyway.
AWB: People who want to subclass to add methods, extend or override some behavior. You're not actually changing the exotic type, hence the constructor signature you want is basically the same as the normal class. So you have to define a custom @@create simply to transform the arguments.
ARV: I think that subclassing builtins will happen relatively frequently but it is VERY rare to then change it later.
YK: For this reason, I think people will forget to use the proper pattern, and thus screw their subtypes.
AWB: There is another approach. What we've done with @@create is split things into two halves. The way to solve this problem, doesn't have to be done at the spec level, one way is that you simply split out the initialization logic into a distinct method.
BE: I want to revisit. We are late in the game. I'm concerned we're hanging too much onto classes. I want to maybe push builtins into syntax or something else. Inventing all this stuff in the new^ proposal is a lot of new stuff, it's too late in schedule, ahead of implementation. DH's proposal hoists new object creation out of [[Construct]] which is also a change. Can we stick with ES6 and do what we want later?
DD: I see we have a few choices. Make implementors swallow @@create is designed, but implementors are very unhappy.
BE: Can we do things in the spec that do not create language level lock in?
MM: If we just do what's in draft ES6 there are too many observables because @@create is called by [[Construct]]?
MM: Lock in is that @@create makes uninit objects observable?
AWB: Nothing says an exotic object can't override it's construct internal method to not call @@create
YK: I think the thing to keep in mind that we want HTML Element to be subclassabe...
AWB: ...they can just keep overriding.
MM: What does Date do presently?
AWB: It invokes @@create and returns an uninitialized slot and blows up if you try to use its methods
MM: That is an observable state that user code can come to count on so it precludes future design that breaks such user code
DD: I think moving @@create into dom might work if you want to avoid locking it down at the language level
AWB: DOM objects can define a new create internal method. Their method can call @@create passing all the arguments.
BE: Marc's point about Date is interesting, though I believe Date can be done at user level. But since it throws, haven't we reserved right to say that we can change that in the future.
MM: I haven't had enough time to think this through. I really don't want to see us get locked in to what's in Draft ES6. What i'm trying to illustrate is that even to evaluate how bad lock in IS is something we can't do with confidence during this meeting.
AWB: Biggest lock-in that I see is that we lock in
super()in a constructor. That's the path.MM: Here are the 4 choices I see. Draft ES6. New^. Dave's proposal. Slip the schedule.
AWB: Or my @@create original design. Draft ES6 plus pass arguments to @@create.
MM: That has same issue with transform of cosntructor arguments, but it lacks having to rethink [[Construct]] path.
DD: I'd like to advocate for new^. I'd like to go through the objections and state why I don't those objections are good and I want to know the temperature of the room.
new^as syntax: weird but rarely usedthis = new super(...)I think is great, it makes clear how JS works and how it's different from other languagesBE: We should take a break. But we should not slip schedule. We can talk about the rest, but I want to emphasize that we should be risk averse and avoid locking ourselves into a bad path.
DH: the
this =and thenew^has a lot of machinery -- static analysis, if you say it is one thing and another. My point is not that it's absolutely wrong but it's a lot of risk.BE: I think we're out of time for 6.
MM: I believe that if slipping is off the table, all the remaining choices are dangerous -- given that we have to make a decision, only one I would be willing is new^ or remove classes.
(general surprise)
BE: paths:
MM: If doesn't find #2 acceptable, that includes #5, #7
NM: #2 should note that it exposes uninitialized state.
YK: Subclassing DOM, @@create returns dummy object, return new super
BT: least risk: punt on all this discussion and let people come up with subclassing protocols that meet needs
.#6 results in syntactic lock-in. Devs will write
super()and then we can't dothis = new super()later.MM: If we do #6 does it preclude having a future proposal with TDZ, unfulfilled this
DD/AWB: It would work if we do the "Domenic variation" in the future, with a default
this = Object.create(new^.prototype)if there is nothis =.RW: #6 is a failure, we've told developers for years now that classes meant subclassing built-ins and we're taking it away.
DH: Unfortunately, implementors brought issues at the last minute.
BE: So we're talking about #5 then
AWB: Agree.
BE: Motion... w/o judging
new^, #3 is too much and risks the slip anywayRW: Seconded.
MM: By same rule, #4
BE: #6 remains, the developers suffer
AWB: Too much work
BE: #6 is out
YK: It's not clear that #2 is definitively broken, recall.
AWB: It's up to @@create to return a safe object
BE: BZ pointed out that there are places in the DOM where you want to alloc memory of a specific size. You don't want to alloc and re-alloc.
YK: There are already checks that exist.
BE: If you want to allocate the right size, you need the arguments.
AWB: All the types that are in ES6, that have size constraints are actually being dealt with in the spec.
BE: Mark also disliked #2 because you can call
B[@@create]()and get back some blank object.MM: A defensive class doesn't leak
thisduring the construction process and a client can't get access and therefore no data dependent accessYK: Still have extra cost in addition checks
MM: Two brands per object
BE: Not going to work, will lose on performance
DD/YK/DH: (discussion of IDL)
EA: Most of the time DOM bindings don't have constructors
BE: What about the size constraints?
EA: Can work around it
AWB: The most common case is an oridinary object
MM: The zero brand and two brand cases...
AWB: There is already logic in the spec that handles multiple stage initializations
ARB: Not convinced that #6 is off.
MM: I understand the workload issue, but what are the
ARB:
new^is easier than @@create, could come soonerRW: Can you explain?
ARB:
YK: I think they have to change for new^ also
ARB: no, allocation code path is neither decoupled nor exposed nor mutable under that proposal.
DH: Alternative design idea: treat the allocation as a proxy trap, with special hooks in to allow you to override it, e.g. in class syntax.
MM: 8. @@create -> [[Create]], no Symbol.create.
AWB: Instead of @@create method, have create slot on function objects and construct method calls it if it's there.
gist.github.com/bterlson/95ab741efa0bbd57f19d
MM/AWB: you could prevent it from being overriden in ES6
AWB: it's not a trap, it's private---perhaps private-inheritable---state of the function.
BE: 8. Constructor [[create]] slot
ARB: Can mutate the the prototype after the fact, so NOT inherited
DH: would implementers say that any time you subclass Array you get a deopt?
Array[[Create]] = function (...args) { return %ArrayCreate%(this.prototype, ...args); };MM: I'm finding this quite attractive. Let's go back to the risk issue. If this turns out to work, how can we at this meeting gain enough confidence in it?
DH: biggest issue is any syntax for a custom allocator
AWB/BE: we should defer
DH: but note that there is no way we could do this without syntax in the meantime.
(Discussion of why 7 sucks and this new 8 is not bad.)
Key point: [[Create]] is NOT exposed or expressed in user ES6 code (for now).
DD: what about the observable uninitialized object via subclasses?
BE: [[Create]] is called before subclass constructor ever happens so you cannot in fact see the unobservable thing.
DH: Oh i see; we don't even need a minimal reflective API.
AWB: Note that, if you wanted to just define a function that was useable as a constructor but inherited/copied its create behavior from someone else, you could just do
class MyFuncWithCopiedCreate extends OrigFuncWithCreate {}MM: Does anyone object to #8
DH: Making sure, #8 is similar to #4 and more similar to #7. The only diff between 4 vs 7 is in 7: construct calls @@create internally; but in 4: it's hoisted out into @@create func.
ARB: Do uninitiliazed objects become unobservable?
AWB: ...since these things are closely coupled, it's not observable where you do it
ARB: Could remove init checks then
AWB: Checks aren't observable
MM: Or turn them into assertions
BE: Want design by contract in the spec
DH: Because you have no way to define own create slot, can't deal with arg transfers (up the create chain)
AWB: You're doing subclassing because you want the allocation from the builtin. So the way its defined is subclass constructor will have, as its create slot, the value of the create slot of Array (copied down) AWB: When you say
new SubArray(), you'll get Array createDH: Yes, but you can't transform the constructor args passed from SubArray to Array
YK: Note that this only matters for args that affect the allocations
AWB: For ex: @@create for arrays don't care what the size of the arrays is
ARB: Problem: Now design of constructor signature is tied by internals of super class
BE: Yes, for ES6 that's true
DH: This is an inherent part of JS. Distinction between exotic types/normal types. When subclassing exotic types, you must participate in the parent's protocol. You have to know more things in these case (constructor signatures, create sigs, etc)
DD: Dislike that...
BE: Can you get it later [post ES6]? Probably
: Can you do super.apply?
BE: Depends.
: Do it in the TDZ
DH: Any new syntax is too high risk for ES6. #8 while most conservative, it introduces the transform problem without a solution
MM: Can someone clarify that we can get out of the scenario in the future
DH: As long as we have a way in the future of doing something like:
# September 24 2014 Meeting Notes Brian Terlson (BT), Allen Wirfs-Brock (AWB), John Neumann (JN), Rick Waldron (RW), Eric Ferraiuolo (EF), Jeff Morrison (JM), Jonathan Turner (JT), Sebastian Markbage (SM), Istvan Sebestyen (phone) (IS), Erik Arvidsson (EA), Brendan Eich (BE), Domenic Denicola (DD), Peter Jensen (PJ), Eric Toth (ET), Yehuda Katz (YK), Dave Herman (DH), Brendan Eich (BE), Simon Kaegi (SK), Boris Zbarsky (BZ), Andreas Rossberg (ARB), Caridy Patino (CP), Niko Matsakis (NM), Mark Miller (MM), Matt Miller (MMR), Jaswanth Sreeram (JS) ## Object Instantiation Redo (Allen Wirfs-Brock) instantiation-reform-sept2014.pdf AWB: (introducing discussion from last meeting) AWB: how many people here have read these gists? (hands are raised) OK, about half the people... The others are going to have a hard time. Slide 1, 2 Introductory Slide 3 Main Issues - @@create can expose uninitialized instances of built-in and host objects - Necessitates numerous dynamic "is it initialized" checks in order to guarantee the invariants of such objects AWB: The design long holding consensus was found to expose uninit instances. If it's an exotic or built-in with some invariant to maintain, instances may be produced that do not uphold the invariant. - Concerns about the complexity introduced into the specification - DOM APIs suddenly required to track - Looking for a solution that doesn't expose the allocated but uninitialized instance. Slide 4 Original Idea From Claude Pache ```js class C extends B { constructor(...args) { /* 1: preliminary code that doesn't contain calls to a super-method */ /* this in TDZ */ /* 2: call to a super-constructor */ super(...whatever); /* this defined */ /* 3: the rest of the code */ } } ``` - Added "receiver" argument to [[Construct]] that passes the constructor that `new` was originally applied to. - Instead of pre-allocating `this` before entering the constructor, a TDZ exists until the super call Slide 5 Addtional Idea Presented at Last Meeting - `new*` token - Value is the "receiver" parameter from [[Construct]] or undefined if [[Call]] - Can be used to discriminate "called as constructor" and "called as function" - Provides access to original constructor for object intialization/intialization – `Object.create(new*.prototype);` `new*` has been replaced by `new^` - Value of `new^` is the "receiver" argument to [[Construct]]. Undefined if called as a function otherwise. - `new^` chosen as alternative to `new*` since `new*` doesn't align with other uses of *, and new^ seems more appropriate. Slide 7 `new super()` - Use `new super()` rather than `super()` to "invoke superclass" constructor - `new super()` is always a [[Construct]] invocation - `super()` is always a [[Call]] invocation - Didn’t want to further confuse "called as a constructor" and "called as a function". – <id>() -- always means "called as function" – new <id>() – always means "called as constructor" – Even when <id> is `super` Slide 8 `this = new super()` - Original proposal had `this` in TDZ until explicit `super()` call. (now `new super()`) - Invisibly assigned to `this` - Update proposal eliminates the implicit assignment by `new super()`. - But allows an explicit assignment to `this` - Only in constructors - Only a single dynamic assignment - Subsequent assignments `throw ReferenceError` MM: "Allows" explicit assignment to `this`, implies also allowed to call `new super()` without assigning to `this`? AWB: Yes. Example is `Proxy(new super(), {...traps});` Slide 9 `this = <expr>` - RHS of `this` assignment in a constructor isn't limited to `new super();` - May be any object valued expression: ```js this = new super(); this = {x;1, y:2}; this = Object.setPrototypeOf([ ], new^.prototype); this = new Proxy(new super(), handler); ``` Slide 10 Works in both class constructors and function constructors ```js SubArray.__proto__ = Array; SubArray.prototype = Object.create([].prototype); function SubArray(...args) { if (!this^) this = new SubArray(...args); else this = new super(...args); } MM: You can do assignment to `this` when called as a function? AWB: No Slide 11 Default object allocation (Base Classes) - Class constructors without an `extends` and basic (function) constructors... - ...Assign a new oridinary object to `this` if body does not have an explicit `this = `. - These continue to mean the same thing: ```js class Base { constructor(x) { this.x = x; } } function Base(x) { this.x = x; } ``` Slide 12 Unqualified super references - Until now ES6 has said that `super()` means the samething as `super.<method name>()` - Implicit property access - Requires setup using toMethod (implicit or explicit) - `super` in constructor needs to means "this constructor's [[Prototype]]", not "[[HomeObject]].prototype.constructor" - It would be confusing if `super()` means something completely different in a constructor from what it means in an non-constructor method - Is this going to be used as a constructor or a method? function `f() {return super()};` Slide 13 Eliminate unqualified `super` reference in non-constructor methods ```js class Sub extends Base { foo() { super(); // now a syntax error super.foo(); // must say this instead } } ``` - Unqualified `super` only allowed in class constructors and function definitions. - Regular methods must qualify `super` references with a property access. Slide 14 Default Value of `this` in derived constructors that don't assign to `this` - Some alternatives - `this = new super(); // super new with no arguments` - `this = new super(...arguments); // siper new all args` - `this = Object.create(new^.prototype); // oridinary obj` - no value, `this` in TDZ at constructor start - Most controversial part of design discussion BE: Implicit object.create with new^ and subclassing a DOM base class, you end up with wrong thing DD: Error better than not (Domenic just named `new^` "new-hat") AWB: Most preferred is Alternative 4. Slide 15 The Winner: No Default `this` - Eliminates issues of what arguments` to pass to implicit `new super()` - Must assign to `this` in derived constructor before referencing it. DH: In the constructor of a class that extends, no implicit this? Subclass would have to explicitly do something AWB: Yes Question about dead code removal, if `this = ` is in a dead code path AWB: Tooling will have to be updated to understand new class semantics. - Assignment to `this` in a function defintion is meaningless, only works in a class body MM: Any way to make derived constructor, base class and function rules? ```js function f() { this = new super() this.x = 1; } ``` MM: What happens is `f()` is called as a function? AWB: If it includes `this = new super()`: Runtime error AWB: `this = new super()` does a TDZ check Questions about multiple `this = ...` JM: In terms of dead code, linters, minifiers (any tooling) will have to become aware. - Additionally, seems there could esily be incidental refactoring hazards (large constructors getting refactored into smaller ones, moving code around, accidentally breaking contextual auto-allocation). AWB: Yes. ```js // Throws because class C { constructor() { this = undefined; return 5; } } ``` MM: In the absense of a valid return, what would be the problem of returning the `this` value at the end of the constructor, even if the return value is a non-object? BE/AWB: Consistency. This would be new semantics MM: Sufficiently different, maybe not worth taking a chance on. BE: I wanted allow return override. Guaranteed to return an object AWB: If don't explicitly return an object, the `this` value is returned. SM: Difference between assigning to `this` and returning an override? AWB: None YK: No TDZ? BE: Invoke a function with new, the return is 5, not an error, just returns the original object MM: comments about refactoring subclass constructor function to class constructor ```js B.call(this) => this = new super(); ``` (break) Dave Herman and Yehuda Katz present counter proposal atat.pdf Slide 1 Introduction Slide 2 Problem: Can create half baked objects. Slide 3 (examples of Foo[@@create]()) Slide 4 Slide 5 - Uninitialized instances of builtin classes have to be implemented for every tupe in the entire web platform - Uninitialized state Slide 7 Solution: both allocator and constructor get arguments Slide 8 ```js new C(x, y, z) ? do { let obj = C[Symbol.create](x, y, z); obj[[Construc]](x, y, z); } ``` Slide 9 - Builtins do all their work in the allocator. - Constructors are noops. - Impossible to observe uninitialized objects. - Abstractable by WebIDL to avoid spec boilerplate. - Abstractable by WebIDL implementations to avoid implementation boilerplate. Slide 10 ```js Object[Symbol.create] = function() { return Object.create(this.prototype); }; Array[Symbol.create] = function(...args) { let a = %CreateArray%(...args); Object.setPrototypeOf(a, this.prototype); return a; }; ``` Slide 11 ```js class Stack extends Array { top() { if (this.length === 0) { throw new Error("empty stack"); } return this[this.length - 1]; } } class Substack extends Stack { meep() { return "moop"; } } ``` Slide 12 ```js let PointType = new StructType({ x: uint32, y: uint32 }); let ColorPointType = new StructType({ x: uint32, y: uint32, color: string }); ``` Slide 13, 14 TODO: Copy slide Slide 15 MM: Difference between the proposals: - In new hat, case splitting on "if of new hat" - Whereas, in ES6 and DH present, case splitting on @@create vs. constructor BE/AWB/YK/DH: Agree. BE: Clarify: this pertains to cases where you have split initialization and allocation, such as exotic objects, built-ins. Discussion re: do not want to expose uninitialized stuff. DH: issues with previous proposal, aka "new-hat" 1. new-hat syntax is there to distinguish call and construct - Agree that this is an issue to address in itself - There are ways to get this distinction without syntax - No way to wrap call and construct path because we're in declarative code - Too late for new syntax and specifically `new^` itself is not good enough to deliver to community. 2. Making `this` appear "mutable" (disagreements) - This is a bizarre change to the mental model of JavaScript - Appeared that all classes would _require_ assignment to `this` 3. Removal of unqualified super 4. In OO, it's considered an anti-pattern to use explicit conditions over method dispatch 5. Hijacking of the call path - It's reserved for subclasses 6. Have to do ALL of this to participate in subclassing AWB: how does #5 differ from current? It's the same. DH: Any reason why it can't call the construct behavior? AWB: Construct allocates DH: Not in this proposal AWB: Haven't addressed what happens in constructor? DH: (goes back to slide 8) need more here... AWB: Are you proposing that all initialization and allocation happen in @@create? DH: no. MM: When D inherits from B and you `new Derived()` that construct trap of Derived gets called. When Derived constructor calls `super()` does it invoke Base's call trap or construct trap? DH: Need a way to distinguish new and call, but super or direct? YK/BE: have to write another `if` if you want to define subclassable classes DD: overriding the allocator is not part of creating a robust super class YK: argues otherwise. DD: enabling overriding the allocator of the subclass hasn't been a goal BZ: in user code, needed in DOM ...continue. DH: (explaning future friendly-ness of distinguished initialization and allocation) Slide 16, 17 AWB: This is speculation of new forms? YK: For illustration only. Speculate that you will have to build a constructor that defines all aspects of allocation and initialization, forced to figure out how the condition (or whatever userland pattern is) - If we say the constructor is also the allocator, then we're boxed in and will have to deal with that. DH: These speculated forms only illustrate goals. - End up having to bless some protocol that distinguishes allocation and initialization. - (wrap up, summarizing) MM: Options? 1. Implement new-hat 2. Implement alternative @@create 3. Slip schedule? 3 => NO. BZ: Want to see how these prevent uninitialized instances AWB: (restating goals) 1. Self hosting 2. Subclassable built-ins and exotic object 3. DH: Can prevent uninitialized instances from being observed with either proposal RW: For exotic, built-ins and DOM, @@create produces the fully baked instance and constructor is just a no-op. For user code, that's uncommon. ... BZ: I am trying to understand how you can guarantee initialization without exposing half-baked objects DH: The answer is that you move the *strict invariant* initialization into `@@create`. To avoid repetition, you use trusted functions that are allowed access to partially initialized objects and encapsulation, and you only pass the `this` value from `@@create` to those trusted functions. DH: MM: Base class, derived class. The Derived clas is a client of the base class, and it's the responsibility of the Base class. It's often the case of the base class locking down property and that's OK. BZ: Want to see some class that uses "magic". - How does ColorPointType know how to BZ: Does ColorPointType get to see an uninitialized PointType instance? RW: No, because it overrode the one on Point BZ: Wait so where does the initialization of ColorPointType and so forth take place? DH: That's how struct types are defined. RW: What about the examples we worked through last night. YK: I think what's getting lost is that the normal way for people to use this is to ignore @@create. BZ: The normal way is fine, I'm not worried about that. YK: To be clear, what you're saying is fine, but I think it's important for everyone else in the room to know that the normal mode of operation has not changed. AW: You're right but they also won't pass new^? YK: But they will have created a non-subclassable object ARB: I have a question. In the other design, there was a discussion about implicit calls to the superconstructor and whether we should pass the arguments. Both Marc and I made the strong argument that this was not a good idea. As far as I can see, it is doing the exact same thing, but even in a weirder sense, because you're passing the arguments through to the allocator even. DH: That's true. Allocator signatures have to track constructor signatures. This means that if you are passing extra arguments that may be ignored -- ?: Or used in a completely different way -- DH: right -- it means that you have to override @@create if you want there to be a difference ARB: isn't that very common? in all cases where derived constructor changes what is passed to the base cosntructor YK: not my experience at all. I think the common case is that you don't really change the arguments that much or just append arguments -- whcih happens to work ok thanks to JS semantics. DD: I think what will happen is that people will say constructor is an anti-pattern, use @@create so that you only need to do one. ARB: I've not used ES6 classes naturally but I find "transform" is the common case by far in other languages DD: isn't that why you subclass -- to modify constructor? <lots of people talking over each other> MM: you have to have each level of @@create mirror the transform that occurs inside the constructor YK: right MM: do you have a pattern for that which is less onerous than the new^ pattern? YK: I think that this will happen sometime but is less bad than the `if (new^)` pattern AWB: No YK: I guess we have to discuss whether we agree that people should design for RW interjects: Here is the whiteboard example: ``` Function.prototype[@@create] = function() { return O.c(this.prototype); }; class A { } class B extends A { [@@create]() { } constructor() { } } class G extends B { constructor() { ... } } var g = new G(); // because G has no @@create, we execute the @@create from B // it all works out ok ``` RW: Follow: ```js g -> new G() -> (no G[@@create]) -> B[@@create]() // done. ``` If B had no @@create ```js g -> new G() -> (no G[@@create]) -> (now B[@@create]) -> (no A[@@create]) -> default // done ``` DH: What Rick is trying to say is that for non-exotic objects, none of this matters DH: Another way of putting this is that exotic objects are a bifurcation inherent to the space we're in, it's part of JS, and it becomes important to know whether there may be exotic objects involved RW: Point I'm trying to make is that in the *most common case*, userland classes, we don't have to do anything different JM: I can't just stay quiet anymore. I feel like we're overstating how common it is to subclass these kinds of "exotics"/built-ins DH: I want to double down on this. Your prediction is wrong Domenic because I don't see people deciding that they should use the syntactically onerous pattern instead of just using constructor. DD: I'm saying that based on Yehuda's argument, where he says to be robust you must be prepared for exotic objects, this design is superior, it doesn't seem like this design helps. Instead you just move things to @@create. YK: That seems ok to me. To people who want to use exotic object subtyping, we can either say "here are a bunch of tools you can use to create a protocool", or we can tell them "here is something that works fine, but you have to use @@create" DD: In that case, why constructor at all? AWB: I'd like to explain why I walked away from this design. Fundamentally BZ's issue is about data-based invariants that must be established as part of the constructor, there will be a tendency to push those things into @@create. Besides being ugly, @@create has other downsides. Here's the real issue -- establishing these invariants, what does it mean? initialized private state. Let's think about the future. That method, the @@create method is a method on the constructor itself. That means to initialize the private state of the instacnce you have a function or method that is not attached to that instance that has ability to reach inside and get private state. So over here in the @@create method, however we might define it in the future, in the @@create method you can't say "this. at foo". (people talk over each other) MM: Not a capability leak -- if the @@create method is in the same class, it's fine. YK: I agree but I think that's something we have to figure out generally for private state. AWB: I'm saying that the model of putting private state into @@create, a foreign method and not the method of the instance, seems wrong. DH: Here's the thing. @@create is not given an object to produce. MM: I am confused about something Rick made. If you create a class G, just writing a constructor that calls super constructor, this is a broken class, because it didn't provide a parallel @@create that provided the same transform. JM: In case where this is not extending an exotic class, it's ok. In the case of something native, like Date, it becomes important. My overall point is that I think it far less common to subclass Date than to subclass userland/non-native classes. MM: But it's non-compositional. DD: What's attractive about this = new super() is that it works regardless of whether it's a exotic class or not. Otherwise you have to know. JM: I think you're right but we're taking what I perceive as an uncommon case and adding burden to the common case. DD: People want to subclass Array a lot. BE: Not common, not common. JM: Let me avoid word "common" for time being. If we're talking about subclassing an ember view, that is not a builtin. It happens a lot. DD interjects: But what if ember views want to upgrade to typed objects? YK: It makes 'magic class' a part of the public API. DH: Every class has two contracts. Contract to consumer and contract to subclasser. Magicness and exoticness is a thing subtypers have to care about regardless. AWB: Dave, array is an exotic object. I can create a subclass of array today and not care whether it's an exotic object. So one step further. In ES6 as currently spec'd, I want to create a subclass of array, in the constructor I want to do something extra. I just want to log a message or something. I have to do something. In current ES6 design, I have to say super(), decide what arguments to pass, and do my extra code. But again I didn't have to think about whether Array was exotic not. It's only if I'm doing something that somehow interacts with the exoticness that I have to think about it. BE: Domenic made a good point. I do think we have to argue about what's common though. Obviously there are piles of code building class hierarchy from plain objects -- but what if we want to go from an emberview to something using typed objects. Does one proposal require more changes than the other? DD: No NM: I disagree ... YK: Answer with Ember subclassing proxies is that it is a semver incompatible change. I worked through this last night and I think it's ok. DH: It's a drop-in replacement for *clients* but not subclassers. YK: In the new proposal, it requires subtypers to type `this = new super()`, which they may not have had to do. DD: I really like `this= new super()`, it's explicit, it makes more sense to me. BE: But that's not the argument. YK: I don't think we can call it a semver compatible change. NM: Extensibility is a factor. ARB: Generally true, right? NM: Yes. MM: I'm confused -- when I bring up the transforms of the arguments, response I got is that subclassing of exotics is relatively rare, which I agree, form of the argument is that it's rare enough that we shouldn't make regular code have to pay a price for the common case. Let's stipulate this is true -- under that argument, than the `if (new^)` goes away? BE: But you still need `this = new super`, and other changes. YK: But if you remove `if(new^)` you're making decision on behalf of others? MM: If we apply the same counterargument, it doesn't need the `if (new^)`, all it needs more is `super()` becomes `this = new super()` YK: I think you misunderstood the argument. I'm not saying you always have to write `if (new^)`. I'm saying that it is SOMETIMES true that you have to do it. MM: I want to split the argument. In world 1, we are saying we don't want to burden normal code with worrying about subclassing builtins. For code that does not subclass builtins, it shouldn't need to worry about possibility that it might get reused as a subclass of a builtin. We should not need to pay the price. MM: In that world, let's compare new^ to the proposal on the board. In new^, in world 1, if this is normal code, super() becomes `this = new super()` YK: Yes but what this was saying is that IF YOU ARE subclasing something exotic, you need to do idiomatic things to get plausible results. MM: But only on the hypothesized small amount of code that needs to subclass builtins. YK: In the revived @@create, the burden falls on people are subclassing objects, and want to do a transform on the constructor. BZ: And people who don't know if they want to subclass an exotic. BE: I think they are lost anyway. AWB: People who want to subclass to add methods, extend or override some behavior. You're not actually *changing* the exotic type, hence the constructor signature you want is basically the same as the normal class. So you have to define a custom @@create simply to transform the arguments. ARV: I think that subclassing builtins will happen relatively frequently but it is VERY rare to then change it later. YK: For this reason, I think people will forget to use the proper pattern, and thus screw their subtypes. AWB: There is another approach. What we've done with @@create is split things into two halves. The way to solve this problem, doesn't have to be done at the spec level, one way is that you simply split out the initialization logic into a distinct method. BE: I want to revisit. We are late in the game. I'm concerned we're hanging too much onto classes. I want to maybe push builtins into syntax or something else. Inventing all this stuff in the new^ proposal is a lot of new stuff, it's too late in schedule, ahead of implementation. DH's proposal hoists new object creation out of [[Construct]] which is also a change. Can we stick with ES6 and do what we want later? DD: I see we have a few choices. Make implementors swallow @@create is designed, but implementors are very unhappy. BE: Can we do things in the spec that do not create language level lock in? MM: If we just do what's in draft ES6 there are too many observables because @@create is called by [[Construct]]? MM: Lock in is that @@create makes uninit objects observable? AWB: Nothing says an exotic object can't override it's construct internal method to not call @@create YK: I think the thing to keep in mind that we want HTML Element to be subclassabe... AWB: ...they can just keep overriding. MM: What does Date do presently? AWB: It invokes @@create and returns an uninitialized slot and blows up if you try to use its methods MM: That is an observable state that user code can come to count on so it precludes future design that breaks such user code DD: I think moving @@create into dom might work if you want to avoid locking it down at the language level AWB: DOM objects can define a new create internal method. Their method can call @@create passing all the arguments. BE: Marc's point about Date is interesting, though I believe Date can be done at user level. But since it throws, haven't we reserved right to say that we can change that in the future. MM: I haven't had enough time to think this through. I really don't want to see us get locked in to what's in Draft ES6. What i'm trying to illustrate is that even to evaluate how bad lock in IS is something we can't do with confidence during this meeting. AWB: Biggest lock-in that I see is that we lock in `super()` in a constructor. That's the path. MM: Here are the 4 choices I see. Draft ES6. New^. Dave's proposal. Slip the schedule. AWB: Or my @@create original design. Draft ES6 plus pass arguments to @@create. MM: That has same issue with transform of cosntructor arguments, but it lacks having to rethink [[Construct]] path. DD: I'd like to advocate for new^. I'd like to go through the objections and state why I don't those objections are good and I want to know the temperature of the room. - `new^` as syntax: weird but rarely used - `this = new super(...)` I think is great, it makes clear how JS works and how it's different from other languages - hijacking call path -- I don't see a significant difference between writing two methods and writing an if statement - YK: There is no way to differentiate super call by subclass from client - DD: I don't see that as a big problem - YK: We're recasting it as "call constructor without allocation" - requiring protocol creation between super/subclass types - super.draw() -- BE: We should take a break. But we should not slip schedule. We can talk about the rest, but I want to emphasize that *we should be risk averse* and avoid locking ourselves into a bad path. DH: the `this =` and the `new^` has a lot of machinery -- static analysis, if you say it is one thing and another. My point is not that it's absolutely wrong but it's a lot of risk. BE: I think we're out of time for 6. MM: I believe that if slipping is off the table, all the remaining choices are dangerous -- given that we have to make a decision, only one I would be willing is new^ or remove classes. (general surprise) BE: paths: 1. Drop classes (generally no) 2. Stay the course with draft ES6 3. new^ 4. Dave & Yehuda proposal 5. DOM Overrides [[Construct]] to do its thing as necessary. Ugly. This is #2++ 6. Remove @@create, built-ins do what ES5 did: Array subclass constructor was return override - Cannot subclass built-ins 7. Pass args to @@create. This is #2++ MM: If doesn't find #2 acceptable, that includes #5, #7 NM: #2 should note that it exposes uninitialized state. YK: Subclassing DOM, @@create returns dummy object, return new super BT: least risk: punt on all this discussion and let people come up with subclassing protocols that meet needs #6 results in syntactic lock-in. Devs will write `super()` and then we can't do `this = new super()` later. MM: If we do #6 does it preclude having a future proposal with TDZ, unfulfilled this DD/AWB: It would work if we do the "Domenic variation" in the future, with a default `this = Object.create(new^.prototype)` if there is no `this =`. RW: #6 is a failure, we've told developers for years now that classes meant subclassing built-ins and we're taking it away. DH: Unfortunately, implementors brought issues at the last minute. BE: So we're talking about #5 then - #3 is too dangerous this late in the game AWB: Agree. - #2, 5, 7 are minimal spec impact - #6 big spec impact - Crazy to do anything but variations of #2 BE: Motion... w/o judging `new^`, #3 is too much and risks the slip anyway RW: Seconded. MM: By same rule, #4 - User visible, uninitialized instances are too problematic, remove #2 & #5 BE: #6 remains, the developers suffer AWB: Too much work BE: #6 is out YK: It's not clear that #2 is definitively broken, recall. AWB: It's up to @@create to return a safe object BE: BZ pointed out that there are places in the DOM where you want to alloc memory of a specific size. You don't want to alloc and re-alloc. YK: There are already checks that exist. BE: If you want to allocate the right size, you need the arguments. AWB: All the types that are in ES6, that have size constraints are actually being dealt with in the spec. BE: Mark also disliked #2 because you can call `B[@@create]()` and get back some blank object. MM: A defensive class doesn't leak `this` during the construction process and a client can't get access and therefore no data dependent access YK: Still have extra cost in addition checks MM: Two brands per object BE: Not going to work, will lose on performance DD/YK/DH: (discussion of IDL) EA: Most of the time DOM bindings don't have constructors BE: What about the size constraints? EA: Can work around it AWB: The most common case is an oridinary object MM: The zero brand and two brand cases... - Constructor needs check the initialization brand AWB: There is already logic in the spec that handles multiple stage initializations ARB: Not convinced that #6 is off. - Can we agree that #6 keeps all the other options open? MM: I understand the workload issue, but what are the ARB: `new^` is easier than @@create, could come sooner RW: Can you explain? ARB: - all allocation codepaths have to change and do "virtual" calls - adding plenty of checks for unitialized objects - @@create is mutable, so every allocation gets deoptimized as soon as someone changes some @@create. - can't easily be inlined YK: I think they have to change for new^ also ARB: no, allocation code path is neither decoupled nor exposed nor mutable under that proposal. DH: Alternative design idea: treat the allocation as a proxy trap, with special hooks in to allow you to override it, e.g. in class syntax. MM: 8. @@create -> [[Create]], no Symbol.create. AWB: Instead of @@create method, have create slot on function objects and construct method calls it if it's there. https://gist.github.com/bterlson/95ab741efa0bbd57f19d MM/AWB: you could prevent it from being overriden in ES6 AWB: it's not a trap, it's private---perhaps private-inheritable---state of the function. BE: 8. Constructor [[create]] slot - own _not_ inherited - no exposed to user code - DEFER Reflect API called with args ARB: Can mutate the the prototype after the fact, so NOT inherited DH: would implementers say that any time you subclass Array you get a deopt? ```js Array[[Create]] = function (...args) { return %ArrayCreate%(this.prototype, ...args); }; ``` MM: I'm finding this quite attractive. Let's go back to the risk issue. If this turns out to work, how can we at this meeting gain enough confidence in it? DH: biggest issue is any syntax for a custom allocator AWB/BE: we should defer DH: but note that there is no way we could do this without syntax in the meantime. (Discussion of why 7 sucks and this new 8 is not bad.) Key point: [[Create]] is NOT exposed or expressed in user ES6 code (*for now*). DD: what about the observable uninitialized object via subclasses? BE: [[Create]] is called before subclass constructor ever happens so you cannot in fact see the unobservable thing. DH: Oh i see; we don't even need a minimal reflective API. AWB: Note that, if you wanted to just define a function that was useable as a constructor but inherited/copied its create behavior from someone else, you could just do `class MyFuncWithCopiedCreate extends OrigFuncWithCreate {}` MM: Does anyone object to #8 DH: Making sure, #8 is similar to #4 and more similar to #7. The only diff between 4 vs 7 is in 7: construct calls @@create internally; but in 4: it's hoisted out into @@create func. ARB: Do uninitiliazed objects become unobservable? AWB: ...since these things are closely coupled, it's not observable where you do it ARB: Could remove init checks then AWB: Checks aren't observable MM: Or turn them into assertions BE: Want design by contract in the spec DH: Because you have no way to define own create slot, can't deal with arg transfers (up the create chain) AWB: You're doing subclassing because you want the allocation from the builtin. So the way its defined is subclass constructor will have, as its create slot, the value of the create slot of Array (copied down) AWB: When you say `new SubArray()`, you'll get Array create DH: Yes, but you can't transform the constructor args passed from SubArray to Array YK: Note that this only matters for args that affect the allocations AWB: For ex: @@create for arrays don't care what the size of the arrays is ARB: Problem: Now design of constructor signature is tied by internals of super class BE: Yes, for ES6 that's true DH: This is an inherent part of JS. Distinction between exotic types/normal types. When subclassing exotic types, you must participate in the parent's protocol. You have to know more things in these case (constructor signatures, create sigs, etc) DD: Dislike that... BE: Can you get it later [post ES6]? Probably : Can you do super.apply? BE: Depends. : Do it in the TDZ DH: Any new syntax is too high risk for ES6. #8 while most conservative, it introduces the transform problem without a solution MM: Can someone clarify that we can get out of the scenario in the future DH: As long as we have a way in the future of doing something like: ```js class Stack extends Array { new() { // overrides the create -- strawman syntax only!! return []; } constructor() { ... } } DH: Gives a way to transform the args MM: If transforming args up construct chain, need a parallel transformation up the 'new' chain? DH: Yes MM: The burden of doing the transformation twice is too awkward. DH: No question there's a cost. Seems livable to me, but... BE: What's alternative? AWB: There's kind of a workaround: Proxy. Proxy overrides construct. Could filter args in construct method of a proxy. DH: Imagine mixin that you extend from MM: Satisfied it's possible AWB: I'm satisfied it's *probably* possible -- not sure yet though DD: Should talk about promises. Specifically about subclassing: I think if we moved everything into @@create, Promise methods would call this.@@create instead of this.constructor, then could have own custom subclass constructors BT: No because .then() ...?? base class blocks all subclasses BE: There are circumstances where you walk the subclass heirarchy to base class [discussion about promise implications] DD: I haven't thought about it enough to really say. I don't like the proxy thing, but... YK: Could imagine a thing that works like a proxy, but isn't actually a proxy BE: A mixin seems good DD: Shame that we, by default, need this heirarchy. MM: Let me try out a scenario that DD and I will find attractive: If we start with #8, then after ES6 want to get to new^, if syntactic occurrance of "new super" then we don't call our local create, and therefore there's no prob with args transform MM: I think that just works YK: All I would say is that #8 seems future proof to that MM: Yes. DD: That's good, I still like new^ and would be good option for ES7 AWB: Would be helpful if proponents of new^, as we update the spec, looked at the spec and made sure it works (for the future) DD: In the world of #8, user code that wants to call super class just does super()? AWB: Yes MM: With that issue resolved, anyone object to declaring concensus on #8? ARB: Should we sleep on it? RW: Lets record it, then immediately decide on it in the morning first thing. [lots of head nods and agreement mumbles] BE: Gotta revisit trailing commas from yest. I don't think there are any grammar problems, right? BE: I don't know, I don't care. AWB: I guess they're ok, but they have a smell DH: One clarification, is there already a create trap? Are we talking about adding one? AWB: No. There's a construct only. Not going to add one DH: I don't understand the use-a-proxy idea as a solution AWB: Construct trap gets the args, it transforms DH: Obviously sub-optimal, but at least expressable and we can work on it DH: [repeats] Would be nice to have good syntax eventually, but good for now. #### Conclusion/Resolution - #8 - https://gist.github.com/bterlson/1fe0b0dc0ef3e71ff6e3 ## 5.1 Trailing Commas in Function Call Expressions and Declarations (Jeff Morrison) trailing_comma_proposal.pdf JM: Review... ARB: Supported for consistency RW: If people dont want them: use JSHint. No objections otherwise #### Conclusion/Resolution - Stage 1 acceptance ## RegExp Globals DD: RegExp globals reform recap. MM: Can we test on deleted properties? BE: What about a flag? - Per instance - Flag to be determined - Specified in Annex B #### Conclusion/Resolution - Stage 0 acceptance -------------- next part -------------- An HTML attachment was scrubbed... URL: <http://mail.mozilla.org/pipermail/es-discuss/attachments/20141003/df06d7ac/attachment-0001.html>