typeof extensibility, building on my Value Objects slides from Thursday's TC39 meeting

Apologies for something (Postbox?) stripping horizontal spaces out of that ASCII-art table. Retrying.
+-----------------------+------------------------------------------------+
| ... : ... |
+-----------------------+------------------------------------------------+
| Null | ExemplarToTypeofMap.has(val) |
| | ? ExemplarToTypeofMap.get(val) |
| | : "object" |
+-----------------------+------------------------------------------------+
| ... : ... |
+-----------------------+------------------------------------------------+
| Object (value object) | ExemplarToTypeofMap.has(val) |
| | ? ExemplarToTypeofMap.get(val.[[Prototype]]) |
| | : "object" |
+-----------------------+------------------------------------------------+
At the TC39 meeting on Thursday, I joked to Mark (deadpan) that the typeof registry is "as good as the global object". That got big laughs, but seriously, it's better. Apart from the null special-case, it's like a global object where only const is allowed. You can't redefine typeof -- first to define it for a user-defined value object wins.
I forgot to say that the maps are pre-seeded with the built-in strings and exemplars, of course, to prevent user-defined value objects from usurping "function", "string", etc.
Brendan Eich wrote:
Function.setTypeOf(V, U)
1. Let S = ToString(U) 2. Let T = V 3. If T is null then 3a. If S is not "null" and S is not "object", throw 4. Else 4a. If T is not a value object constructor, throw 4b. T = T.prototype 4c. If TypeofToExemplarMap.has(S), throw 5. Call TypeofToExemplarMap.set(S, T) 6. Call ExemplarToTypeofMap.set(T, S)
Correction, see new 4b below:
1. Let S = ToString(U)
2. Let T = V
3. If T is null then
3a. If S is not "null" and S is not "object", throw
4. Else
4a. If T is not a value object constructor, throw
4b. If T and Function are not same-realm, throw
4c. T = T.prototype
4d. If TypeofToExemplarMap.has(S), throw
5. Call TypeofToExemplarMap.set(S, T)
6. Call ExemplarToTypeofMap.set(T, S)
I did not add an exception when the current evaluation context's realm is not the same as Function's -- that seems too restrictive, forbidding script in the main window from fixing up typeof for same-origin code that it loads into an iframe.
Again, comments welcome (cc'ing Allen since he is realm-master; ES1-5 left realm implicit and singular, contrary to reality in browsers).

Suggestion: put this evolving spec into a Gist or something similar.
Axel Rauschmayer wrote:
Suggestion: put this evolving spec into a Gist or something similar.
Definitely -- trying not to work all weekend, s'all. Also practicing release-early/often on es-discuss.
Thanks for reading! Any other comments?
- Absolutely love the multiple dispatch stuff (slide 10).
- A bit uneasy about typeof, which will never properly express JavaScript’s “class” hierarchy. That is bound to always confuse people (already: “wait – I thought a function was an object”, worse with value objects). But maybe it’s the best we can do. Being able to fix typeof null is awesome, though.
- Also love that we’ll get 64 bit integers etc. (slide 11) and user-definable value objects.
W.r.t. to #1: Couldn’t we extend that to universal multiple dispatch?
const removeAll = new MultiMethod(); // not a realistic example
removeAll.addMethod(Array, Set, (arr, set) => { ... });
removeAll.addMethod(Object, Map, (obj, map) => { ... });
For the plus operator:
import { operatorPlus } from '@operators';
operatorPlus.addMethod(Point, Number, (a, b) => Point(a.x + b, a.y + b);
operatorPlus.addMethod(Number, Point, (a, b) => Point(a + b.x, a + b.y);
operatorPlus.addMethod(Point, Point, (a, b) => Point(a.x + b.x, a.y + b.y);
In my experience, multiple dispatch and single dispatch are highly complementary. Reenskaug and Coplien seem to have come to a similar conclusion (well, at least I would combine single dispatch and multiple dispatch to implement the DCI ideas): www.artima.com/articles/dci_vision.html
Axel Rauschmayer wrote:
A bit uneasy about typeof, which will never properly express JavaScript’s “class” hierarchy.
What class hierarchy? primitives have wrappers but those are not what typeof tests. If you believe
Object
|
+-------+-------+----+----+----...
| | | |
Boolean Number String Function
then where are boolean, number, and string? There's no Value (ValueObject) either.
Suppose we build a value object class (constructor/prototype) hierarchy:
Object
|
+-------+-------+----+----+--------+
| | | | |
Boolean Number String Function Value
|
+-------+-------+----+----+------+------...
| | | | |
boolean number string int64 uint64 ...
Would we be better off? Not only is there an abstract Value constructor, but what about double? int32? uint32?
In general we would need a semi-lattice like the one depicted here:
asmjs.org/spec/latest/subtypes.png
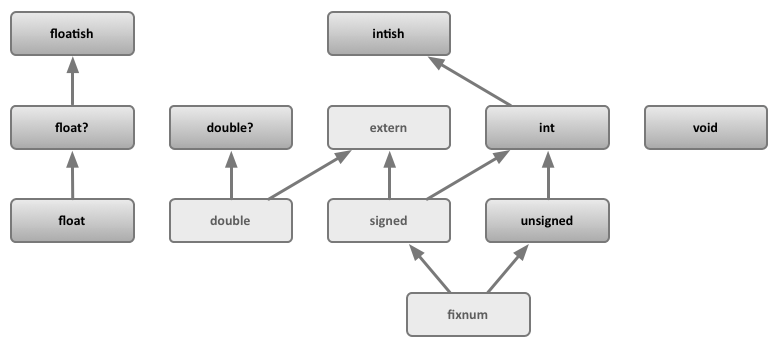{kind=link}
but without the "-ish", fixnum, and extern types, and with the concrete types listed above.
That is bound to always confuse people (already: “wait – I thought a function was an object”, worse with value objects).
I don't hear that typeof f == "function" confuses people -- that's JS's callable predicate for native (ordinary) objects. I do hear sometimes that people wish typeof a == "array" worked, mainly because instanceof doesn't work cross-frame.
Anyway, typeof 0L were to result in "object" we'd have not only confusion but lack of a useful value-type query operator. TC39 agreed on the use-case, and it upholds the (typeof x == typeof y && x == y) <=> (x === y) invariant.
But maybe it’s the best we can do.
There is no total class hierarchy describing all values in JS. If you think we should retrofit one, make that case.
Being able to fix typeof null is awesome, though.
One could complain that mutating a typeof registry (map-pair) is a hack, but hacks sometimes are the best thing in a pinch, and I don't see a better way.
Also love that we’ll get 64 bit integers etc. (slide 11) and user-definable value objects.
W.r.t. to #1: Couldn’t we extend that to universal multiple dispatch?
const removeAll = new MultiMethod(); // not a realistic example removeAll.addMethod(Array, Set, (arr, set) => { ... }); removeAll.addMethod(Object, Map, (obj, map) => { ... });
You can do this with proxies and enough work. Operators are special forms already, so have special semantics that I'm generalizing a bit to be only somewhat more special-cased (the last special case, a general extension mechanism).
Much as I am a fan of dead languages with multimethods, I'd rather leave it at this for ES7.
For the plus operator:
import { operatorPlus } from '@operators'; operatorPlus.addMethod(Point, Number, (a, b) => Point(a.x + b, a.y + b); operatorPlus.addMethod(Number, Point, (a, b) => Point(a + b.x, a + b.y); operatorPlus.addMethod(Point, Point, (a, b) => Point(a.x + b.x, a.y + b.y);
This is another way of realizing Function.defineOperator. Is it worth the extra boilerplate? The strong reason to prefer it is to have operatorPlus as a function value to pass around and invoke separately on arbitrary values.
One could have both APIs, Function.defineOperator layered on the @operators API. Function.defineOperators was Christian's suggestion and I see the appeal: convenience for users as well as VM implementors (I've implemented it under the hood in SpiderMonkey's int64/uint64 patch).
An HTML attachment was scrubbed... URL: esdiscuss/attachments/20130728/cb63d557/attachment
But maybe it’s the best we can do.
There is no total class hierarchy describing all values in JS. If you think we should retrofit one, make that case.
There is a subclass relationship between types in JavaScript. instanceof is aware of it, typeof isn’t. So I think my complaint is better phrased like this: Why do people have to be aware of the difference between primitives and objects when it comes to choosing between typeof and instanceof?
Much as I am a fan of dead languages with multimethods, I'd rather leave it at this for ES7.
I understand and agree with the desire to keep the language small. That is a very good argument against multiple dispatch (MD).
But I don’t see how it matters whether languages using MD are dead or not (which they are not: Clojure is popular, Stroustrup has written a proposal for adding them to C++, etc.).
MD is very useful for working with data (web services, JSON, etc.), where you don’t want to (or can’t) encapsulate behavior with data. Design-wise, they make functions aware of object-orientation so that you can use them to implement algorithms that span multiple classes (as binary operators do).
Axel Rauschmayer wrote:
But maybe it’s the best we can do.
There is no total class hierarchy describing all values in JS. If you think we should retrofit one, make that case.
There is a subclass relationship between types in JavaScript. instanceof is aware of it, typeof isn’t. So I think my complaint is better phrased like this: Why do people have to be aware of the difference between primitives and objects when it comes to choosing between typeof and instanceof?
This is a question about JS today? Obviously (as discussed on twitter) people have to be aware. ("hi" instanceof String) is false and must be.
Again, are you suggesting a retrofit along the lines I diagrammed, so that ("hi" instanceof string) would be true? Note that "subclass relationship between types" in JS is not the same as implicitly-converts-to relations, nor is it obvious what should be a subclass. int32 and uint32 of double? Rather, all three of number, the new value type that's not much different from double (possibly abstract)? Consider
0 instanceof int32 0 instanceof float32 0 instanceof uint32 0 instanceof double 0 instanceof number
If you want some of these to result in true without hacking instanceof to test different things from the "subclass relationship" (prototype chain of LHS reaching .prototype property value of RHS), you'll have to put some under others. We could put all under number and eliminate double, since number is no more abstract and double is no more concrete except as a storage type. But double or float64, at least as a typename alias for number, is useful when dealing with typed arrays.
To be useful, such a value-object class hierarchy has to do more than look pretty. If the subtype semi-lattice that we want for bit-preserving conversions (implicit or explicit) is much different, and the new interior nodes are abstract, then I question the utility of it -- even if it enables "hi" instanceof string.
Much as I am a fan of dead languages with multimethods, I'd rather leave it at this for ES7.
I understand and agree with the desire to keep the language small. That is a very good argument against multiple dispatch (MD).
But I don’t see how it matters whether languages using MD are dead or not (which they are not: Clojure is popular, Stroustrup has written a proposal for adding them to C++, etc.).
I championed generic functions for ES4, remember?
MD is very useful for working with data (web services, JSON, etc.), where you don’t want to (or can’t) encapsulate behavior with data. Design-wise, they make functions aware of object-orientation so that you can use them to implement algorithms that span multiple classes (as binary operators do).
That's all fine but again: not ES7. First, operators for value objects.
So I think my complaint is better phrased like this: Why do people have to be aware of the difference between primitives and objects when it comes to choosing between typeof and instanceof?
This is a question about JS today? Obviously (as discussed on twitter) people have to be aware. ("hi" instanceof String) is false and must be.
Good point. They have to understand that String is not a constructor for (primitive) strings.
Again, are you suggesting a retrofit along the lines I diagrammed, so that ("hi" instanceof string) would be true?
I don’t have a definite answer for how to best fix this, but it would be lovely if we could. I find it challenging myself ATM and pity newcomers. So I’m insisting more on the problem than on my solution.
But I don’t see how it matters whether languages using MD are dead or not (which they are not: Clojure is popular, Stroustrup has written a proposal for adding them to C++, etc.).
I championed generic functions for ES4, remember?
True. ;-)
MD is very useful for working with data (web services, JSON, etc.), where you don’t want to (or can’t) encapsulate behavior with data. Design-wise, they make functions aware of object-orientation so that you can use them to implement algorithms that span multiple classes (as binary operators do).
That's all fine but again: not ES7. First, operators for value objects.
Makes sense. Maybe the syntax/API for setting up operators can be designed in a way that keeps the option open of adding complete multiple dispatch later (or via a library).
Axel Rauschmayer wrote:
Makes sense. Maybe the syntax/API for setting up operators can be designed in a way that keeps the option open of adding complete multiple dispatch later (or via a library).
Function.defineOperator has a rationale (convenience, boilerplate reduction) even in a world where Function.prototype.addMethod (or perhaps F.p.overload is a better name) exists, so I think we're good.
Axel Rauschmayer wrote:
Again, are you suggesting a retrofit along the lines I diagrammed, so that ("hi" instanceof string) would be true?
I don’t have a definite answer for how to best fix this, but it would be lovely if we could.
Would it? Having string as well as String might be useful at the limit, but is string.prototype the same object as String.prototype, or an Object instance full of the same methods?
I find it challenging myself ATM and pity newcomers.
Are newcomers going to face string and String? If yes, that seems worse than status quo. If no, then you're hiding string from them, not String, and recommending typeof to distinguish string from other values -- so how is that different from status quo?
It seems to me the issue is not newcomers or whether instanceof can be made to supplant typeof (cross-frame issues remain but they vex any extensible mechanism too, as I conceded in the earlier posts talking about realms). The issue is whether we want a bunch of "constructors" (not callable via 'new', remember) in a tree that spans some kind of subtype semi-lattice -- but which may not pay for its user-facing-complexity costs.
So I’m insisting more on the problem than on my solution.
There are trade-offs but I don't see a clean win. Going back to 1995 and making "everything an object" (and no typeof at all? cross-window was a thing then too) is a dream. We should stick to realistic alternatives and weigh them carefully.

I am not sure I completely understand what a realm is but I am assuming it is similar to a set of primodials (say an iframe in a browser).
Unless I am really misreading your examples, I do not think the new proposal overcomes the problems of harmony:typeof_null.
If Function.setTypeOf dynamically affects subsequent use of typeof, then action-at-a-distance problems will persist. If one library adopts one convention regarding typeof null and another a different one, then these libraries will not be useable together. Similarly, the use of such a library in a program would suddenly cause existing typeof conventions to break. Finally, given the following snippet:
var x = typeof a;
f();
var y = typeof b;
it would be surprising to me if x !== y just because f() happened to call Function.setTypeOf().
Especially if you make typeof extensible, this kind of action-at-a-distance will be a hazard to developers.
If we must make typeof extensible, it would be less of a hazard if the effect of the declaration was lexically scoped. In that case, it would genuinely affect only new code and maintain the invariants of legacy code.
๏̯͡๏ Jasvir Nagra wrote:
I am not sure I completely understand what a realm is but I am assuming it is similar to a set of primodials (say an iframe in a browser).
Tes: realm is the primordials (memoized internally at start of world; older ECMA-262 specs wrote of "the original value of Array.prototype", see latest draft at harmony:specification_drafts and search for "realm" for more).
Unless I am really misreading your examples, I do not think the new proposal overcomes the problems of harmony:typeof_null. If Function.setTypeOf dynamically affects subsequent use of typeof, then action-at-a-distance problems will persist. If one library adopts one convention regarding typeof null and another a different one, then these libraries will not be useable together.
Right, so don't do that, or else dynamically save and restore for the desired result. There's no assumption of hostile code here, as usual you have to trust what you include into your single-frame/window (realm) TCB, etc.
Similarly, the use of such a library in a program would suddenly cause existing typeof conventions to break.
The intended use-case is where application top-level script changes typeof null and proceeds with vetted library code.
In general, lexical scope is best. Could we have a pragma that changes typeof null? We deferred real pragma syntax from ES6, perhaps from Harmony (no more modes!), and "use null typeof sanity"; or whatever is not enough, as it doesn't choke old browsers, so doubles the testing burden.
It is possible to write typeof-testing code that copes with either "null" or "object" as the typeof null, as we've discussed in past TC39 meetings; this supports the idea of top-level dynamic opt-in with vetted libraries.
Finally, given the following snippet:
var x = typeof a; f(); var y = typeof b;it would be surprising to me if x !== y just because f() happened to call Function.setTypeOf().
If you meanted typeof a; the second time, not typeof b; -- I agree, it would. Almost as surprising as typeof null == "object" :-P.
Especially if you make typeof extensible, this kind of action-at-a-distance will be a hazard to developers.
We could forbid switching back and forth between "null" and "object", indeed. Then the repair is one-time, per-realm, but unlike with novel value object types, code could witness two values for typeof null: "object" and later "null". No going back to "object", however. Any problems with that, from an SES point of view?
If we must make typeof extensible, it would be less of a hazard if the effect of the declaration was lexically scoped. In that case, it would genuinely affect only new code and maintain the invariants of legacy code.
Lexical scope wants new syntax delimited by the scope, which we could certainly do. The value objects proposal so far has stuck with APIs, for object detection and because operators rendezvous in the heap through prototype lookup of @@ADD, @@ADD_R, etc. But their bindings to +, *, etc. could indeed also be lexical -- we'd have scoped operator-to-multimethod bindings, which may be overkill but could be good for isolation and composition, as usual.
Syntax could be the way to go, though. But before I throw in the towel, could you comment on one-time (const-like) typeof definition approach for novel value objects? And of course the "object" => "null" dynamic change for typeof null.

Various thoughts...
Slipping in support for redefining 'typeof null' feels like the sort of thing I sometimes try to squeeze through ;-)
Why is setTypeOf attached to Function? There would seem to be very little to naturally associate it with Function. I suppose it's because that's where you put 'defineOperator'. Even there, the association with Function seems tenuous. I actually find a stronger association with Math. But really, why aren't these just functions export from the reflection module or some other standard module?
Regarding realm associations? What is the rationale for making the typeof binding per realm? I would expect the people would want (at least operator associated) value object instances to be freely used across realms, just like numbers, strings, and booleans are. And I don't think you have mentioned anything about defineOperator creating realm specific operator bindings. So, I would expect that in: x + 1 the value of x may be (for example) a decimal number defined in a different realm and that the + gets appropriately dispatched to do a Decimal+Number add operation. In that case, I would also expect typeof x to give me 'decimal' (or whatever) as registered in the original defining domain.
There also seems like a possible consistancy that should maintained between new typeof values and the new Literal Syntax suffix support. Anywhere you can say '0m' you probably should be able to say typeof x == 'decimal. But this seems like it should be lexically scoped rather than Realm scoped.
I would argue that Functioun.setTypeOf(null, "null") is actually a different kind of beast and one that you would want to be lexically scoped. The difference is that it is changing the meaning of a pre-existing operator applied to a pre-existing value. This reinterpretation really does need to be scoped only to code that wants to see that change.
Also see below:
On Jul 28, 2013, at 2:24 PM, Brendan Eich wrote:
Brendan Eich wrote:
Function.setTypeOf(V, U)
1. Let S = ToString(U) 2. Let T = V 3. If T is null then 3a. If S is not "null" and S is not "object", throw 4. Else 4a. If T is not a value object constructor, throw 4b. T = T.prototype 4c. If TypeofToExemplarMap.has(S), throw 5. Call TypeofToExemplarMap.set(S, T) 6. Call ExemplarToTypeofMap.set(T, S)Correction, see new 4b below:
1. Let S = ToString(U) 2. Let T = V 3. If T is null then 3a. If S is not "null" and S is not "object", throw 4. Else 4a. If T is not a value object constructor, throw 4b. If T and Function are not same-realm, throw
setTypeOf itself has a realm association so that's what I would expect you would test against. You don't really have access to Function. It might have been passed in as the this value or might not if setTypeOf was invoked via call or been hung-off of a namespace object.
But just like setPrototypeOf, I'm not sure that it matters which Realm you retrieved your setTypeOf function from. If each Realm has it's own TypeToExemplarMap than everything will be fine if setTypeOf just gets the map associated with T's (actually V.prototype) Realm.

From: Allen Wirfs-Brock [allen at wirfs-brock.com]
Why is setTypeOf attached to Function? There would seem to be very little to naturally associate it with Function. I suppose it's because that's where you put 'defineOperator'. Even there, the association with Function seems tenuous. I actually find a stronger association with Math. But really, why aren't these just functions export from the reflection module or some other standard module?
+1, I was wondering the same. Just put these as functions in a module; they are not methods of Function. In particular, I assume they don't do new this() anywhere like the array statics do.
Allen Wirfs-Brock wrote:
Various thoughts...
Thanks, it's pre-strawman here so all are welcome.
Slipping in support for redefining 'typeof null' feels like the sort of thing I sometimes try to squeeze through ;-)
Heh. It's one reason for Function as the static namespace (no methods on null). More below.
Why is setTypeOf attached to Function? There would seem to be very little to naturally associate it with Function. I suppose it's because that's where you put 'defineOperator'.
I mentioned why already: to accomodate (null | value-object-constructor) as the first parameter.
Even there, the association with Function seems tenuous. I actually find a stronger association with Math.
I took lots of Math in school, never ran across typeof :-P.
But really, why aren't these just functions export from the reflection module or some other standard module?
Could do that instead -- Reflect.defineOperator, Reflect.setTypeOf for now as Tom has done with Proxies (awaiting the name of the standard reflection module).
Regarding realm associations? What is the rationale for making the typeof binding per realm? I would expect the people would want (at least operator associated) value object instances to be freely used across realms, just like numbers, strings, and booleans are.
Why would you expect methods attached to prototypes to be cross-realm? They wouldn't be even for double-dispatch, in this sense: you would not know which "@@ADD" or (Python) "add" you were calling across a realm. In an OOP sense this works, but for dyadic operators as Chambers, et al. argue, it's wrong. The multimethod approach fits the problem precisely, but only same-realm or (if cross-realm) only if you load the same value object extension in both realms.
All methods have realm dependencies. If you are assuming built-in status means string primitives get the same indexOf, e.g., even that can be monkeypatched to diverge cross-realm.
And I don't think you have mentioned anything about defineOperator creating realm specific operator bindings.
You missed the point Luke made at the meeting: see the v + u operator semantics slide, where p intersect q is based on function object indentity, and functions are realm-specific without extra work (e.g., loading a value object extension once in an iframe and ensuring all instances come from that iframe -- artificial, contrived!).
So, I would expect that in: x + 1 the value of x may be (for example) a decimal number defined in a different realm and that the + gets appropriately dispatched to do a Decimal+Number add operation.
Which one, though? However the dispatch works, methods on prototypes are per-realm.
In that case, I would also expect typeof x to give me 'decimal' (or whatever) as registered in the original defining domain.
If you mean x's domain that makes typeof depend on a symbol-named prototype property, or equivalent relationship. But that is not wanted, because per the meeting any attempt to redefine a value object's typeof should throw, but we can't control what's defined or redefined on prototypes.
As Jasvir suggested, lexically scoped extensions compose better, and in that case, typeof x would definitely not depend on x's realm if it weren't same-realm with the scope of that expression.
There also seems like a possible consistancy that should maintained between new typeof values and the new Literal Syntax suffix support.
Cross-realm inconsistency due to prototypes differing is a thing in JS.
Anywhere you can say '0m' you probably should be able to say typeof x == 'decimal. But this seems like it should be lexically scoped rather than Realm scoped.
No, lexical wouldn't cut it if x flowed into the evaluation context's realm from realm 2 where 0m was originally evaluated and assigned to x.
You really do need pan-realm typeof (as the built-ins provide), which is not a thing in JS for user-code to extend.
I would argue that Functioun.setTypeOf(null, "null") is actually a different kind of beast and one that you would want to be lexically scoped. The difference is that it is changing the meaning of a pre-existing operator applied to a pre-existing value. This reinterpretation really does need to be scoped only to code that wants to see that change.
Ok, good feedback between you and jasvir. This suggests using the syntax I mooted:
typeof null = "null"; // lexically rebind typeof null
/* new code here */
typeof null = "object"; // restore for old code after
setTypeOf itself has a realm association so that's what I would expect you would test against. You don't really have access to Function. It might have been passed in as the this value or might not if setTypeOf was invoked via call or been hung-off of a namespace object.
Right, thanks.
But just like setPrototypeOf, I'm not sure that it matters which Realm you retrieved your setTypeOf function from. If each Realm has it's own TypeToExemplarMap than everything will be fine if setTypeOf just gets the map associated with T's (actually V.prototype) Realm.
Does that rescue the realm-dependency in your view?
Domenic Denicola wrote:
From: Allen Wirfs-Brock [allen at wirfs-brock.com]
Why is setTypeOf attached to Function? There would seem to be very little to naturally associate it with Function. I suppose it's because that's where you put 'defineOperator'. Even there, the association with Function seems tenuous. I actually find a stronger association with Math. But really, why aren't these just functions export from the reflection module or some other standard module?
+1, I was wondering the same. Just put these as functions in a module; they are not methods of
Function. In particular, I assume they don't donew this()anywhere like the array statics do.
They don't, and I'm happy to move them to Reflect (straw name) for now. Thanks,

On 7/29/2013 4:04 PM, Brendan Eich wrote:
Regarding realm associations? What is the rationale for making the typeof binding per realm? I would expect the people would want (at least operator associated) value object instances to be freely used across realms, just like numbers, strings, and booleans are.
Why would you expect methods attached to prototypes to be cross-realm? They wouldn't be even for double-dispatch, in this sense: you would not know which "@@ADD" or (Python) "add" you were calling across a realm. In an OOP sense this works, but for dyadic operators as Chambers, et al. argue, it's wrong. The multimethod approach fits the problem precisely, but only same-realm or (if cross-realm) only if you load the same value object extension in both realms.
All methods have realm dependencies. If you are assuming built-in status means string primitives get the same indexOf, e.g., even that can be monkeypatched to diverge cross-realm.
And I don't think you have mentioned anything about defineOperator creating realm specific operator bindings.
You missed the point Luke made at the meeting: see the v + u operator semantics slide, where p intersect q is based on function object indentity, and functions are realm-specific without extra work (e.g., loading a value object extension once in an iframe and ensuring all instances come from that iframe -- artificial, contrived!).
So, I would expect that in: x + 1 the value of x may be (for example) a decimal number defined in a different realm and that the + gets appropriately dispatched to do a Decimal+Number add operation.
Which one, though? However the dispatch works, methods on prototypes are per-realm.
For value objects, I think it would be problematic if 1m + iframeEval('1m') or 1m === iframeEval('1m') didn't work. It would
also be a shame if my user-overloaded new Point(0, 0) + iframeEval('[5, 5]') didn't work.
Potential solution for builtin value objects: all realms actually shared the same value object constructor and prototype and these are deeply frozen from a null realm to prohibit side channels.
Potential solution for user defined operator overloading:
defineOperator could also take a string for any of the builtin classes
that allowed it to work cross realm:
defineOperator('+', addPointAndArray, Point, 'Array')
Bonus points if it works with a class extending any realm's builtin,
like class MyArray extends iframeEval('Array') {}.
Brandon Benvie wrote:
For value objects, I think it would be problematic if
1m + iframeEval('1m')or1m === iframeEval('1m')didn't work. It would also be a shame if my user-overloadednew Point(0, 0) + iframeEval('[5, 5]')didn't work.
Really? How often does cross-frame application arise (never mind application of operator-proxy functions)?
Potential solution for builtin value objects: all realms actually shared the same value object constructor and prototype and these are deeply frozen from a null realm to prohibit side channels.
Potential solution for user defined operator overloading:
defineOperatorcould also take a string for any of the builtin classes that allowed it to work cross realm:defineOperator('+', addPointAndArray, Point, 'Array')Bonus points if it works with a class extending any realm's builtin, like
class MyArray extends iframeEval('Array') {}.
Sorry, but I don't think this works (I considered it). What is the locus of sharing? Same origin (say we define origin as a property of realm and equate all realms with same origin). Still not right: disjoint window/frame-graphs should not share. Ok, use the now-standard ancestor-based algorithm: still wrong in cases of windows that cooperate loosely and not in all operator overloadings.
You can't have your cake and eat it: either value objects are extensible, in which case realm matters; or they're not extensible, period full stop.
On 7/29/2013 4:47 PM, Brendan Eich wrote:
Brandon Benvie wrote:
For value objects, I think it would be problematic if
1m + iframeEval('1m')or1m === iframeEval('1m')didn't work. It would also be a shame if my user-overloadednew Point(0, 0) + iframeEval('[5, 5]')didn't work.Really? How often does cross-frame application arise (never mind application of operator-proxy functions)?
I used iframeEval as an example because it's something we might see now (though I agree with that you it's not common enough to design for). However, I was thinking this could happen pretty easily given the new module system. One might have a few constellations of modules each with their own Loader and intrinsic interacting through function calls (say some set of modules may be sandboxed by an outer application). I don't know that this is something people will actually do, but I thought that one of the features of the module system was to make it possible and easy to do.
You can't have your cake and eat it: either value objects are extensible, in which case realm matters; or they're not extensible, period full stop.
Indeed, I was actually envisioning builtin value objects as being totally frozen, up through the prototype chain. I don't see how you get around the fact that you can't know which realm the return value should come from. I'm guessing you want those prototypes extensible though.
I don't see an issue with using a string to identify a builtin type for
user operator overloading though, since you don't end up with multiple
copies of the same user type. If my application (which uses multiple
realms, like say loading all my third party modules in a sandbox realm),
if I can specify how my Point class operator overloads with 'Array', it
seems like it should work just fine with any values coming out of those
modules. An Array would be identified the same way as it is currently in
the ES6 spec: any object that is an Exotic Array Object would match
'Array'; for map, any object that has [[MapData]] matches 'Map', etc
(basically how Object.prototype.toString figures out what to call
something).
Honing in on disagreement (rest is ok).
Brandon Benvie wrote:
I don't see an issue with using a string to identify a builtin type for user operator overloading though, since you don't end up with multiple copies of the same user type. If my application (which uses multiple realms, like say loading all my third party modules in a sandbox realm), if I can specify how my Point class operator overloads with 'Array', it seems like it should work just fine with any values coming out of those modules
Including modules loaded in other realms?
. An Array would be identified the same way as it is currently in the ES6 spec: any object that is an Exotic Array Object would match 'Array'; for map, any object that has [[MapData]] matches 'Map', etc (basically how
Object.prototype.toStringfigures out what to call something).
This still is privileged spec-only/builtin-only territory. How can user-code make a Map-like that has [[MapData]]?

On Mon, Jul 29, 2013 at 5:20 PM, Brendan Eich <brendan at mozilla.com> wrote:
Brandon Benvie wrote:
. An Array would be identified the same way as it is currently in the ES6 spec: any object that is an Exotic Array Object would match 'Array'; for map, any object that has [[MapData]] matches 'Map', etc (basically how
Object.prototype.toStringfigures out what to call something).This still is privileged spec-only/builtin-only territory. How can user-code make a Map-like that has [[MapData]]?
It can't, precisely because the spec is defined in terms of [[MapData]]. If it were instead defined in terms of a SimpleMap with just get/set/has/delete, user-code could handle it. Similarly with other built-ins - they could be defined in terms of a simplified version of themselves.
On 7/29/2013 5:20 PM, Brendan Eich wrote:
Honing in on disagreement (rest is ok).
Brandon Benvie wrote:
I don't see an issue with using a string to identify a builtin type for user operator overloading though, since you don't end up with multiple copies of the same user type. If my application (which uses multiple realms, like say loading all my third party modules in a sandbox realm), if I can specify how my Point class operator overloads with 'Array', it seems like it should work just fine with any values coming out of those modules
Including modules loaded in other realms?
If it's considered a valid use case (sandbox realms/multirealm setups). I thought it was a goal just based on the design of the module system but that may be an incorrect idea.
. An Array would be identified the same way as it is currently in the ES6 spec: any object that is an Exotic Array Object would match 'Array'; for map, any object that has [[MapData]] matches 'Map', etc (basically how
Object.prototype.toStringfigures out what to call something).How can user-code make a Map-like that has [[MapData]]?
I just mean an instance of a Map or a class that extends Map. Essentially all I'm saying is that you match by [[Class]] (which doesn't exist in ES6, but a heuristic to determine what is essentially [[Class]] does exist).
defineOperator('+', addPointAndArray, Point, Array) // matches only
this realm's Arrays defineOperator('+', addPointAndArray, Point, 'Array') // matches any realm's Arrays, [[Class]]
Basically, if Array.isArray(rhs) is true, I'd want it to match
'Array' in operator overloading.
On Jul 29, 2013, at 5:28 PM, Tab Atkins Jr. wrote:
On Mon, Jul 29, 2013 at 5:20 PM, Brendan Eich <brendan at mozilla.com> wrote:
Brandon Benvie wrote:
. An Array would be identified the same way as it is currently in the ES6 spec: any object that is an Exotic Array Object would match 'Array'; for map, any object that has [[MapData]] matches 'Map', etc (basically how
Object.prototype.toStringfigures out what to call something).This still is privileged spec-only/builtin-only territory. How can user-code make a Map-like that has [[MapData]]?
It can't, precisely because the spec is defined in terms of [[MapData]]. If it were instead defined in terms of a SimpleMap with just get/set/has/delete, user-code could handle it. Similarly with other built-ins - they could be defined in terms of a simplified version of themselves.
There seems to be some confusion here that is similar to thing that we are also discussing in the "Proxy for Array transparency" thread...
There are various forms of "typing" that are used in the Es spec. and by ES programmers. One of them is branding based upon the presence of various "internal data properties".
The ES Map specification implicitly defined a Map interface (let's call this Mapish) as the behavior of its properties. Anybody can implemented an object, in anyway they want, that supports the Mapish interface. Such an Mapish object won't have (and doesn't need) a [[MapData]] internal property. Any Map client (that only uses normal property [[Get]], [[Set]], [[Invoke]] operations) will work fine on any Mapish object, regardless of the existence of a [[MapData]] property.
On the other hand, every class that implements Mapish, will have to have someway that its instances store the actual state required to fulfill the Mapish interface. The bodies of the methods that are part of a specific Mapish implementation will need to be coded using algorithms that understand how its instances store that state. And, since ES methods can be easily detached from an object and reattached to another. The methods of any particular Mapish implementation need to verify that the actual this value they are invoked upon use the stored state representation that the method understands.
That is all that testing for [[MapData]] does in the ES6 spec. [[MapData]] is really acting as a surrogate for "the actual Map state representation chosen by your favorite ES engine". It makes sure that when Map.prototype.get tries to navigate the hash table or binary tree, or whatever accessed at, let's say, offset +32 from the pointer to the this value it won't get a seg fault (or worse) because the actual this value is only 16 bytes long.
Nobody, other than implementers of Map really needs to think about [[MapDate]] or similar private state of specified built-ins.
Brandon Benvie wrote:
On 7/29/2013 5:20 PM, Brendan Eich wrote:
Honing in on disagreement (rest is ok).
Brandon Benvie wrote:
I don't see an issue with using a string to identify a builtin type for user operator overloading though, since you don't end up with multiple copies of the same user type. If my application (which uses multiple realms, like say loading all my third party modules in a sandbox realm), if I can specify how my Point class operator overloads with 'Array', it seems like it should work just fine with any values coming out of those modules
Including modules loaded in other realms?
If it's considered a valid use case (sandbox realms/multirealm setups). I thought it was a goal just based on the design of the module system but that may be an incorrect idea.
Let's say realms connected via property references (window.frames[0], e.g.) or addressable by window.open form a realm-clique, sometimes called a constellation -- too long, how about "world" (set of realms reachable from one or more members of the set).
What world is the locus of operator overloads including typeof? This is not something we've spec'ed for ES6.
. An Array would be identified the same way as it is currently in the ES6 spec: any object that is an Exotic Array Object would match 'Array'; for map, any object that has [[MapData]] matches 'Map', etc (basically how
Object.prototype.toStringfigures out what to call something).How can user-code make a Map-like that has [[MapData]]?
I just mean an instance of a Map or a class that extends Map. Essentially all I'm saying is that you match by [[Class]] (which doesn't exist in ES6, but a heuristic to determine what is essentially [[Class]] does exist).
defineOperator('+', addPointAndArray, Point, Array) // matchesonly this realm's Arrays defineOperator('+', addPointAndArray, Point, 'Array') // matches any realm's Arrays, [[Class]]
Basically, if
Array.isArray(rhs)is true, I'd want it to match'Array'in operator overloading.
I got that, it's a nice API -- but it requires us to define world-of-realms-that-can-share-references, no?
Brendan Eich wrote:
I just mean an instance of a Map or a class that extends Map. Essentially all I'm saying is that you match by [[Class]] (which doesn't exist in ES6, but a heuristic to determine what is essentially [[Class]] does exist).
defineOperator('+', addPointAndArray, Point, Array) // matchesonly this realm's Arrays defineOperator('+', addPointAndArray, Point, 'Array') // matches any realm's Arrays, [[Class]]
Basically, if
Array.isArray(rhs)is true, I'd want it to match'Array'in operator overloading.I got that, it's a nice API -- but it requires us to define world-of-realms-that-can-share-references, no?
Say we define a world as set of reachable realms. Both the HTML processing model and DOM API calls can extend the world. When that happens for new realm R with global G, given the
defineOperator('+', addPointAndArray, Point, 'Array') // matches any realm's Arrays, [[Class]]
call, an observer watching for new realms would
defineOperator('+', addPointAndArray, Point, G.Array)
The Point.prototype.@@ADD array (hmm, should be a Set -- array was from a pre-ES6-Set state of play) already has an element with value addPointAndArray due to the first call, so this call would find that element, and then only add addPointAndArray to G.Array.prototype.@@ADD_R's array.
Then code evaluated in R that uses Point (the shared singleton) and G.Array (say via an array literal -- arrays are not value objects but let's skip that!) can use +.
This could be made to work. Is it the right design? It leaves Point as a world-shared singleton, while using each realm's 'Array'. Point.prototype.@@ADD and other sets grow quite large (not a problem if we use Set, O(1) lookup). There's a shared mutable Point, Point.prototype, Point.prototype.* channel, world-wide.
As noted, operators-via-methods creates realm-dependency. But if we add worlds of realms, we could distinguish world-globals and load things once, where the sharing is wanted. Unwanted sharing is still a hazard and some realms will want their own unshared value objects and operator methods.
On 7/30/2013 9:39 AM, Brendan Eich wrote:
Brendan Eich wrote:
I just mean an instance of a Map or a class that extends Map. Essentially all I'm saying is that you match by [[Class]] (which doesn't exist in ES6, but a heuristic to determine what is essentially [[Class]] does exist).
defineOperator('+', addPointAndArray, Point, Array) // matchesonly this realm's Arrays defineOperator('+', addPointAndArray, Point, 'Array') // matches any realm's Arrays, [[Class]]
Basically, if
Array.isArray(rhs)is true, I'd want it to match'Array'in operator overloading.I got that, it's a nice API -- but it requires us to define world-of-realms-that-can-share-references, no?
Say we define a world as set of reachable realms. Both the HTML processing model and DOM API calls can extend the world. When that happens for new realm R with global G, given the
defineOperator('+', addPointAndArray, Point, 'Array') // matches any realm's Arrays, [[Class]]
call, an observer watching for new realms would
defineOperator('+', addPointAndArray, Point, G.Array)
The Point.prototype.@@ADD array (hmm, should be a Set -- array was from a pre-ES6-Set state of play) already has an element with value addPointAndArray due to the first call, so this call would find that element, and then only add addPointAndArray to G.Array.prototype.@@ADD_R's array.
Then code evaluated in R that uses Point (the shared singleton) and G.Array (say via an array literal -- arrays are not value objects but let's skip that!) can use +.
This could be made to work. Is it the right design? It leaves Point as a world-shared singleton, while using each realm's 'Array'. Point.prototype.@@ADD and other sets grow quite large (not a problem if we use Set, O(1) lookup). There's a shared mutable Point, Point.prototype, Point.prototype.* channel, world-wide.
As noted, operators-via-methods creates realm-dependency. But if we add worlds of realms, we could distinguish world-globals and load things once, where the sharing is wanted. Unwanted sharing is still a hazard and some realms will want their own unshared value objects and operator methods
That design seems to fit the behavior I was thinking, but I was envisioning something more along the lines of an alteration to the algorithm:
For the expression v + u
- Let p = a new List
- Let pOverloads = v.[Get]
- If pOverloads is not undefined
- If pOverloads is not a Set throw a TypeError
- Else append the values of pOverloads to p
- If v has a [[SharedOverloads]] internal property
- Let pSharedOverloads = v.[SharedOverloads]
- Append pSharedOverloads to p
- If p has no items throw a TypeError
- Let q = a new List
- Let qOverloads = u.[Get]
- If qOverloads is not undefined
- If qOverloads is not a Set throw a TypeError
- Else append the values of qOverloads to q
- If u has a [[SharedOverloads]] internal property
- Let qSharedOverloads = u.[SharedOverloads]
- Append qSharedOverloads to q
- If q has no items throw a TypeError
- Let r = p intersect q
- If r.length != 1 throw a TypeError
- Let f = r[0]; if f is not a function, throw
- Evaluate f(v, u) and return the result
[[SharedOverloads]] would return a cross-realm list such that
realmA.int64.[[SharedOverloads]](@ADD) === realmB.int64.[[SharedOverloads]](@ADD).
Using a string in addOperator for one of the types checks the string against the list of builtins that have [[SharedOverloads]] and adds it to that list.
I fully admit that this may be overkill to support an edge case, and as I said I don't even know if it's expected for multi-realm usage to happen.
On Mon, Jul 29, 2013 at 3:12 PM, Brendan Eich <brendan at mozilla.com> wrote:
๏̯͡๏ Jasvir Nagra wrote:
I am not sure I completely understand what a realm is but I am assuming it is similar to a set of primodials (say an iframe in a browser).
Hi Jasvir,
Tes: realm is the primordials (memoized internally at start of world; older ECMA-262 specs wrote of "the original value of Array.prototype", see latest draft at doku.php?id=harmony: specification_draftsharmony:specification_draftsand search for "realm" for more).
Unless I am really misreading your examples, I do not think the new
proposal overcomes the problems of ** doku.php?id=harmony:typeof_**nullharmony:typeof_null. If Function.setTypeOf dynamically affects subsequent use of typeof, then action-at-a-distance problems will persist. If one library adopts one convention regarding typeof null and another a different one, then these libraries will not be useable together.
Right, so don't do that, or else dynamically save and restore for the desired result. There's no assumption of hostile code here, as usual you have to trust what you include into your single-frame/window (realm) TCB, etc.
If the semantics are non-lexical, I don't think the save & restore technique could be easily adopted by a library unless the library did the save on entry to every function and a restore on exit. Take for example, if jQuery wanted to use a sensible typeof but a program using jQuery did not. You'd also have to maintain the option of opting in and out of sensible-typeof which unfortunately means we cannot adopt your suggestion of "opting and no going back" below.
Similarly, the use of such a library in a program would suddenly cause
existing typeof conventions to break.
The intended use-case is where application top-level script changes typeof null and proceeds with vetted library code.
In general, lexical scope is best. Could we have a pragma that changes typeof null? We deferred real pragma syntax from ES6, perhaps from Harmony (no more modes!), and "use null typeof sanity"; or whatever is not enough, as it doesn't choke old browsers, so doubles the testing burden.
I was also thinking about a pragma but if they're deferred and not usable, how about instead of a flag that changes the semantics of the existing typeof, introducing the better typeof say on Function instead. Again it would mean legacy code and code that was uninterested in adopting a better typeof would continue to work unaffected.
You've managed to successfully root out so many of the dynamic scoping modes (arguments.caller, with etc) that it feels worthwhile to try to avoid reintroducing one if we can avoid it.
It is possible to write typeof-testing code that copes with either "null"
or "object" as the typeof null, as we've discussed in past TC39 meetings; this supports the idea of top-level dynamic opt-in with vetted libraries.
Finally, given the following snippet:
var x = typeof a; f(); var y = typeof b;
it would be surprising to me if x !== y just because f() happened to call Function.setTypeOf().
If you meanted typeof a; the second time, not typeof b; -- I agree, it would. Almost as surprising as typeof null == "object" :-P.
gack Sorry - complete braino.
Especially if you make typeof extensible, this kind of
action-at-a-distance will be a hazard to developers.
We could forbid switching back and forth between "null" and "object", indeed. Then the repair is one-time, per-realm, but unlike with novel value object types, code could witness two values for typeof null: "object" and later "null". No going back to "object", however. Any problems with that, from an SES point of view?
I don't think we'd want to allow the switching of values for SES - it would be a small (single bit) implicit communication channel and more importantly an interference hazard from hostile code. If at initialization a SES module declared which typeof it wanted, that would be sufficient. This is of course equivalent to a lexical scope for the entire SES module.
If we must make typeof extensible, it would be less of a hazard if the
effect of the declaration was lexically scoped. In that case, it would genuinely affect only new code and maintain the invariants of legacy code.
Lexical scope wants new syntax delimited by the scope, which we could certainly do. The value objects proposal so far has stuck with APIs, for object detection and because operators rendezvous in the heap through prototype lookup of @@ADD, @@ADD_R, etc. But their bindings to +, *, etc. could indeed also be lexical -- we'd have scoped operator-to-multimethod bindings, which may be overkill but could be good for isolation and composition, as usual.
A bit behind on reading up the operator proposals - it's on my list!
Syntax could be the way to go, though. But before I throw in the towel,

On Tue, Jul 30, 2013 at 7:15 PM, Brandon Benvie <bbenvie at mozilla.com> wrote:
I fully admit that this may be overkill to support an edge case, and as I said I don't even know if it's expected for multi-realm usage to happen.
Nodes moving between documents (with their own globals) is certainly something that occurs frequently in the DOM. (We have not figured out whether the prototype object needs to change, whether it does not change and we run into garbage collection hell, or whether we mutate the identity of the object. I suspect if we defined operators for these kind of objects they would invoke adopt, depending on functionality.)
XMLHttpRequest is also used across globals and its base URL is tied to the document base URL of the global it originated from (workers work different).
Not sure how relevant either of these cases here, but platform objects definitely move between globals and given that you have synchronous access to everything the implications are generally not thought through and it's all expected to just work.
I thought this was not all that interoperable. What exactly are the intersection semantics? Not object identity change!
Tab is still looking for a MapLite (tm) that can be customized with hooks. Obviously to avoid infinite regress, the MapLite bottoms out as native, and the hooks are on the outside (in Map). Tab, do I have this right?
The even simpler course is to keep Map as spec'ed and make DOM or other specs work harder. Trade-offs...
On Thu, Aug 1, 2013 at 5:29 PM, Brendan Eich <brendan at mozilla.com> wrote:
Tab is still looking for a MapLite (tm) that can be customized with hooks. Obviously to avoid infinite regress, the MapLite bottoms out as native, and the hooks are on the outside (in Map). Tab, do I have this right?
Right. Map has a medium-sized interface, with several methods that don't provide new capabiltiies, but only convenience/performance. As well, I expect the interface to grow over time.
Making a Map subclass that needs to audit its data on input or output is thus difficult, because when a new method gets added to Map, either it's able to pierce through your interventions and get at the raw data directly, or it simple doesn't work until you update. Even for the existing methods, you have to manually override the conveniences; just overriding delete() just protect you against a clear().
MapLite has the smallest possible useful semantics for a Map (basically, the same semantics that the spec uses in terms of meta-operations), and thus is useful as an interception target. You can then just subclass Map and only override the MapLite at its core, secure in the knowledge that new methods will Just Work (tm) in terms of the provided bedrock operations on the MapLite.
The even simpler course is to keep Map as spec'ed and make DOM or other specs work harder. Trade-offs...
The reason I'm really pushing on this is that it's not just DOM (we've already made the trade-off there, by adding [MapClass] to WebIDL), but user-space as well. I can't make a safe Counter class that's built on a Map unless I make the tradeoff above.
But this is a tangent. ^_^
On Fri, Aug 2, 2013 at 1:21 AM, Brendan Eich <brendan at mozilla.com> wrote:
I thought this was not all that interoperable. What exactly are the intersection semantics? Not object identity change!
Gecko will change the prototype. WebKit will keep the prototype until garbage collection has run at which point it will do the identify change thing, as I understand it. Geoffrey might do an experiment at some point to do the identify change directly. I'm not sure how Internet Explorer tackles this.
However, by and a large things like node.appendChild() et al just work and developers rarely hit those edges of non-interoperability.
On Aug 1, 2013, at 5:36 PM, Tab Atkins Jr. wrote:
On Thu, Aug 1, 2013 at 5:29 PM, Brendan Eich <brendan at mozilla.com> wrote:
Tab is still looking for a MapLite (tm) that can be customized with hooks. Obviously to avoid infinite regress, the MapLite bottoms out as native, and the hooks are on the outside (in Map). Tab, do I have this right?
Right. Map has a medium-sized interface, with several methods that don't provide new capabiltiies, but only convenience/performance. As well, I expect the interface to grow over time.
Making a Map subclass that needs to audit its data on input or output is thus difficult, because when a new method gets added to Map, either it's able to pierce through your interventions and get at the raw data directly, or it simple doesn't work until you update. Even for the existing methods, you have to manually override the conveniences; just overriding delete() just protect you against a clear().
MapLite has the smallest possible useful semantics for a Map (basically, the same semantics that the spec uses in terms of meta-operations), and thus is useful as an interception target. You can then just subclass Map and only override the MapLite at its core, secure in the knowledge that new methods will Just Work (tm) in terms of the provided bedrock operations on the MapLite.
I'm all for extensible abstractions based upon abstract algorithms that decompose into a set of over-ridable primitives. That that is pretty much what the current ES6 specification of Map provides. I assume that we agree that at the core of map there needs to be an encapsulated implementation of a key/value store. The question Tab is asking essentially is whether the methods of Map are too tightly couple to one specific key/value store implementation. Or viewed from another perspective, would ES6 be more flexible if the public abstraction of Map and the default key/value store (Map-lite) were separated into distinct classes.
Let's look at the Map methods to see if it is possible and worthwhile to make it anymore extensible then it already is and whether it makes sense to move some of the functionality into a Map-lite.
'get'/'set'/'delete': The fundamental operations of Map are 'get', 'set', and 'delete'. If you look at the specification of these methods, you will see that they are almost pure primitives dealing with the mechanism of the encapsulated key/value store. If we separated the default key/value store into a separate Map-lite object it would have the equivalent of these methods and 'get'/'set''/delete' on the more generic Map would simply delegate to them. There is very little in the way of policy that could be separated from the default implementation. The major policy decisions within 'get'/'set'/'delete' are 'set' handling of duplicate elements, and 'get'/'delete' handling of missing elements. Map's 'set' over-writes the value of an already existing element, 'get' returns undefined as the value for missing keys, and 'delete' returns false for a missing key. A Map-lite store would still have to have some sort of defaults for these cases and these are good defaults for JS. If you want to change those defaults it is easy to encapsulate or subclass a Map and over-ride these policies with get/set/delete wrappers.
''has': is also an almost pure operation upon the primitive key/value store. It would be possible for a Map-lite to expose a primitive method that combines the capabilities of 'get'/'has' such that Map might define its distinct 'get' and 'has' policies in terms of that combined operation. However the combined operation would require more complex arguments and/or result design and additional logic in the Map-level methods. I think it is more pragmatic to use a default primitive key/value store that directly exposes the default policies and push the complexity of alternative policies into any new abstractions that wants them.
'size' is essentially a primitive of the key/value store.
'clear' could be expressed in terms of key iteration and the 'delete' methods. We haven't talked about iteration yet and whether it needs to be part of a basic key/value store API. But we can skip ahead because 'clear' is really about pragmatics. It's a method that is useful when a client knows it wants to delete all elements from a key/value store. It primarily exists as a channel to convey that intent to lower level implementation layers, based upon the assumption that a bulk delete can probably be performed more efficiently than a bunch of individual deletes. So, even if you have a basic key/value store you will want to have a 'clear' method on it to support such bulk delete use cases.
So ES6 Map with 'get'/'set'/'delete'/'has'/'size'/'clear' is essentially a "Map-lite". What about the rest of Map's methods?
They are all about iteration. There is the 'forEach' method that directly iterates over the keys/values of a Map and 'keys'/'values'/'entries'/@@iterator all of which are used to obtain an iterator over the contents of a map.
So should iteration be part of a Map-lite and should an iteration ordering be mandated. Regard ordering, JS experience shows us that developers generally expect iteration order to be consistent across all implementation. So a Map-lite that supports iteration without a specified order would be an interoperability hazard. If Map-lite had no iteration methods we could still implement forEach and the iterator factories if Map maintain a separate ordering data structure that it updated on every 'set'/'delete' operation. But such a side table is likely to be far less efficient than any means of element ordering that are directly implemented as part of the key/value store. So, so for ES, it makes sense for something like 'forEach' to be part of a Map-lite.
The iterator factory methods of map are all just short-cuts for creating "MapIterator" objects which are current specified as "friends" (in the C++ sense) that know about internal key/value store encapsulated by Map objects. The current spec. for MapInterator was written before we added 'forEach' to Map and arguably it could be re-specified in terms of 'foreach'. However, that may take away some implementation level flexibility. Regardless, it's a possibility that I think I'll look into more deeply.
Where we end up with is that the operations we would want for a Map-lite are get/set/delete/has/size/clear/forEach. They all need to know the implementation details of the underlying key/value store and for pragmatic reasons it doesn't make sense to try to reduce them to a smaller set of primitives.
That is exactly the interface of ES6 Map except that Map adds the trivial iterator factory method. It simply isn't worth having the added complexity of distinct Map and Map-lite classes simply to not have the iterator factory methods. For ES6 Map is Map-lite
We can debate whether future new methods should be added to Map or be made part of distinct new classes. I'd suggest the latter for most cases. New methods are likely to incorporate domain concepts (eg, DOM stuff) that are not an essential part of the basic key/value store abstraction. It's better to define an appropriate domain specific abstraction that encapsulates a Map (or if you're an old school OO'er subclasses it) than it is to start adding new methods.
The even simpler course is to keep Map as spec'ed and make DOM or other specs work harder. Trade-offs...
The reason I'm really pushing on this is that it's not just DOM (we've already made the trade-off there, by adding [MapClass] to WebIDL), but user-space as well. I can't make a safe Counter class that's built on a Map unless I make the tradeoff above.
Did you mean [[MapData]]? [[MapData]] is just private state of the built-in object. If you're saving that you can't safely define certain abstractions with access to private state mechanism, then I agree you. But trying to turn [[MapData]] into an object level extension mechanism isn't the solution to your general problem.
Allen Wirfs-Brock wrote:
The iterator factory methods of map are all just short-cuts for creating "MapIterator" objects which are current specified as "friends" (in the C++ sense) that know about internal key/value store encapsulated by Map objects. The current spec. for MapInterator was written before we added 'forEach' to Map and arguably it could be re-specified in terms of 'foreach'.
This is a minor point, but internal iteration (forEach) and external (@@iterator) are not the same. How do you avoid rewriting to move the external consumer code into the forEach callback? Rewriting source is out.
However, that may take away some implementation level flexibility. Regardless, it's a possibility that I think I'll look into more deeply.
It's easier to layer internal iteration on external.
Where we end up with is that the operations we would want for a Map-lite are get/set/delete/has/size/clear/forEach. They all need to know the implementation details of the underlying key/value store and for pragmatic reasons it doesn't make sense to try to reduce them to a smaller set of primitives.
That is exactly the interface of ES6 Map except that Map adds the trivial iterator factory method. It simply isn't worth having the added complexity of distinct Map and Map-lite classes simply to not have the iterator factory methods. For ES6 Map is Map-lite
We can debate whether future new methods should be added to Map or be made part of distinct new classes.
I think this is the underlying concern (Tab can confirm).
I'd suggest the latter for most cases. New methods are likely to incorporate domain concepts (eg, DOM stuff) that are not an essential part of the basic key/value store abstraction. It's better to define an appropriate domain specific abstraction that encapsulates a Map (or if you're an old school OO'er subclasses it) than it is to start adding new methods.
We should probably stack hands and even make this more than a suggestion. Between compatibility woes adding to Map.prototype later (see Array.prototype.values and @@unscopeable), and Tab's concern, I am ready to make it policy.
On Fri, Aug 2, 2013 at 12:06 PM, Allen Wirfs-Brock <allen at wirfs-brock.com> wrote:
On Aug 1, 2013, at 5:36 PM, Tab Atkins Jr. wrote:
On Thu, Aug 1, 2013 at 5:29 PM, Brendan Eich <brendan at mozilla.com> wrote:
Tab is still looking for a MapLite (tm) that can be customized with hooks. Obviously to avoid infinite regress, the MapLite bottoms out as native, and the hooks are on the outside (in Map). Tab, do I have this right?
Right. Map has a medium-sized interface, with several methods that don't provide new capabiltiies, but only convenience/performance. As well, I expect the interface to grow over time.
Making a Map subclass that needs to audit its data on input or output is thus difficult, because when a new method gets added to Map, either it's able to pierce through your interventions and get at the raw data directly, or it simple doesn't work until you update. Even for the existing methods, you have to manually override the conveniences; just overriding delete() just protect you against a clear().
MapLite has the smallest possible useful semantics for a Map (basically, the same semantics that the spec uses in terms of meta-operations), and thus is useful as an interception target. You can then just subclass Map and only override the MapLite at its core, secure in the knowledge that new methods will Just Work (tm) in terms of the provided bedrock operations on the MapLite.
I'm all for extensible abstractions based upon abstract algorithms that decompose into a set of over-ridable primitives. That that is pretty much what the current ES6 specification of Map provides. I assume that we agree that at the core of map there needs to be an encapsulated implementation of a key/value store. The question Tab is asking essentially is whether the methods of Map are too tightly couple to one specific key/value store implementation. Or viewed from another perspective, would ES6 be more flexible if the public abstraction of Map and the default key/value store (Map-lite) were separated into distinct classes.
Let's look at the Map methods to see if it is possible and worthwhile to make it anymore extensible then it already is and whether it makes sense to move some of the functionality into a Map-lite.
'get'/'set'/'delete': The fundamental operations of Map are 'get', 'set', and 'delete'. If you look at the specification of these methods, you will see that they are almost pure primitives dealing with the mechanism of the encapsulated key/value store. If we separated the default key/value store into a separate Map-lite object it would have the equivalent of these methods and 'get'/'set''/delete' on the more generic Map would simply delegate to them. There is very little in the way of policy that could be separated from the default implementation. The major policy decisions within 'get'/'set'/'delete' are 'set' handling of duplicate elements, and 'get'/'delete' handling of missing elements. Map's 'set' over-writes the value of an already existing element, 'get' returns undefined as the value for missing keys, and 'delete' returns false for a missing key. A Map-lite store would still have to have some sort of defaults for these cases and these are good defaults for JS. If you want to change those defaults it is easy to encapsulate or subclass a Map and over-ride these policies with get/set/delete wrappers.
''has': is also an almost pure operation upon the primitive key/value store. It would be possible for a Map-lite to expose a primitive method that combines the capabilities of 'get'/'has' such that Map might define its distinct 'get' and 'has' policies in terms of that combined operation. However the combined operation would require more complex arguments and/or result design and additional logic in the Map-level methods. I think it is more pragmatic to use a default primitive key/value store that directly exposes the default policies and push the complexity of alternative policies into any new abstractions that wants them.
Yes, I agree that 'has' is useful as a primitive alongside get/set/delete. At the very least, it means that you don't need a sentinel value to distinguish a missing key from a key set to the default value.
'size' is essentially a primitive of the key/value store.
It can be defined in terms of iterations, but I'm fine with this being primitive because it's such a small data leak. If you're subclassing Map such that the naive .size isn't what you want, you're doing something rather unusual.
'clear' could be expressed in terms of key iteration and the 'delete' methods. We haven't talked about iteration yet and whether it needs to be part of a basic key/value store API. But we can skip ahead because 'clear' is really about pragmatics. It's a method that is useful when a client knows it wants to delete all elements from a key/value store. It primarily exists as a channel to convey that intent to lower level implementation layers, based upon the assumption that a bulk delete can probably be performed more efficiently than a bunch of individual deletes. So, even if you have a basic key/value store you will want to have a 'clear' method on it to support such bulk delete use cases.
I'm less convinced of 'clear' - it's clearly a product of iteration + 'delete'. You're right that it's often more efficient to do directly, though.
So ES6 Map with 'get'/'set'/'delete'/'has'/'size'/'clear' is essentially a "Map-lite". What about the rest of Map's methods?
They are all about iteration. There is the 'forEach' method that directly iterates over the keys/values of a Map and 'keys'/'values'/'entries'/@@iterator all of which are used to obtain an iterator over the contents of a map.
So should iteration be part of a Map-lite and should an iteration ordering be mandated. Regard ordering, JS experience shows us that developers generally expect iteration order to be consistent across all implementation. So a Map-lite that supports iteration without a specified order would be an interoperability hazard. If Map-lite had no iteration methods we could still implement forEach and the iterator factories if Map maintain a separate ordering data structure that it updated on every 'set'/'delete' operation. But such a side table is likely to be far less efficient than any means of element ordering that are directly implemented as part of the key/value store. So, so for ES, it makes sense for something like 'forEach' to be part of a Map-lite.
The iterator factory methods of map are all just short-cuts for creating "MapIterator" objects which are current specified as "friends" (in the C++ sense) that know about internal key/value store encapsulated by Map objects. The current spec. for MapInterator was written before we added 'forEach' to Map and arguably it could be re-specified in terms of 'foreach'. However, that may take away some implementation level flexibility. Regardless, it's a possibility that I think I'll look into more deeply.
Where we end up with is that the operations we would want for a Map-lite are get/set/delete/has/size/clear/forEach. They all need to know the implementation details of the underlying key/value store and for pragmatic reasons it doesn't make sense to try to reduce them to a smaller set of primitives.
Yes. You need exactly one of the iteration methods as a primitive. Today's world, where you have to override all four of them if you want to override any of them, feels very similar to forcing someone to override all six boolean comparisons rather than just defining them all in terms of less-than and equality. (Like Brendan, I prefer the default to be one of the external iterators, either keys() or entries().)
That is exactly the interface of ES6 Map except that Map adds the trivial iterator factory method. It simply isn't worth having the added complexity of distinct Map and Map-lite classes simply to not have the iterator factory methods. For ES6 Map is Map-lite
Except for the iterators and maybe 'clear', yes.
We can debate whether future new methods should be added to Map or be made part of distinct new classes. I'd suggest the latter for most cases. New methods are likely to incorporate domain concepts (eg, DOM stuff) that are not an essential part of the basic key/value store abstraction. It's better to define an appropriate domain specific abstraction that encapsulates a Map (or if you're an old school OO'er subclasses it) than it is to start adding new methods.
I find it quite likely that we'll add more Map methods in the future. For example, .update() from Python's dict is easy to write yourself, but it's useful often enough that it's likely worthwhile to add. Same with .pop(), .popitem(), and setdefault(). It bothers me that if an author monkey-patches these onto Map.prototype themselves, they'll automatically work on my subclass (because they're defined in terms of the primitives that I override), but if we then add it to the language, it'll break (because it's defined in terms of [[MapData]], which I can't intercept access to).
(Though, Brendan says in his response that we probably shouldn't, and should instead just pledge to only add new methods onto Map subclasses. I don't think that's a particularly good idea, but it would address most of my problem.)
The even simpler course is to keep Map as spec'ed and make DOM or other specs work harder. Trade-offs...
The reason I'm really pushing on this is that it's not just DOM (we've already made the trade-off there, by adding [MapClass] to WebIDL), but user-space as well. I can't make a safe Counter class that's built on a Map unless I make the tradeoff above.
Did you mean [[MapData]]? [[MapData]] is just private state of the built-in object. If you're saving that you can't safely define certain abstractions with access to private state mechanism, then I agree you. But trying to turn [[MapData]] into an object level extension mechanism isn't the solution to your general problem.
No, I mean [MapClass]. dev.w3.org/2006/webapi/WebIDL/#MapClass It's a WebIDL
extended attribute - the syntax has no relation to your use of [[foo]] in the ES spec. It declares the interface to be a Map subclass, setting Map.prototype on its prototype chain and providing default implementations of several Map methods for you. (This is especially helpful on the spec level, as you can then just define what the map entries are and then methods like get() are auto-defined for you.)
On Aug 2, 2013, at 12:59 PM, Tab Atkins Jr. wrote:
On Fri, Aug 2, 2013 at 12:06 PM, Allen Wirfs-Brock ...
'size' is essentially a primitive of the key/value store.
It can be defined in terms of iterations, but I'm fine with this being primitive because it's such a small data leak. If you're subclassing Map such that the naive .size isn't what you want, you're doing something rather unusual.
More importantly, if you actually have a reason to taking the size of a Map (perhaps to preallocate an ArrayBuffer to hold a copy of the values) then you probably would like to avoid iteration size performance hit to compute the size value.
...
I'm less convinced of 'clear' - it's clearly a product of iteration + 'delete'. You're right that it's often more efficient to do directly, though.
Again it's pragmatics. If you have a reason for doing clears you probably want them to be fast.
Yes. You need exactly one of the iteration methods as a primitive. Today's world, where you have to override all four of them if you want to override any of them, feels very similar to forcing someone to override all six boolean comparisons rather than just defining them all in terms of less-than and equality. (Like Brendan, I prefer the default to be one of the external iterators, either keys() or entries().)
Sure, the four methods are trivial and all the actual semantics are in the "MapIterator" class. The only reason you have to over-ride four methods is that in the current design the reference to the "MapIterator" constructor is private and hard coded. They way we would do this in Smalltalk is to have an over-ridable getMapIterator (we wouldn't actually say "get") accessor property on Map.prototype (don't have one of those either...) that return the MapIterator factory. You'd only over-ride that one accessor (plus write a new iterator and factory).
I'd be fine with doing this approach. I've generally, tried to minimize the number of OO hacks I've used in the spec. because not lot of people are familiar with them and others are uncomfortable with this style of extensibility.
That is exactly the interface of ES6 Map except that Map adds the trivial iterator factory method. It simply isn't worth having the added complexity of distinct Map and Map-lite classes simply to not have the iterator factory methods. For ES6 Map is Map-lite
Except for the iterators and maybe 'clear', yes.
and iterator can be fixed as above.
We can debate whether future new methods should be added to Map or be made part of distinct new classes. I'd suggest the latter for most cases. New methods are likely to incorporate domain concepts (eg, DOM stuff) that are not an essential part of the basic key/value store abstraction. It's better to define an appropriate domain specific abstraction that encapsulates a Map (or if you're an old school OO'er subclasses it) than it is to start adding new methods.
I find it quite likely that we'll add more Map methods in the future. For example, .update() from Python's dict is easy to write yourself, but it's useful often enough that it's likely worthwhile to add. Same with .pop(), .popitem(), and setdefault(). It bothers me that if an author monkey-patches these onto Map.prototype themselves, they'll automatically work on my subclass (because they're defined in terms of the primitives that I override), but if we then add it to the language, it'll break (because it's defined in terms of [[MapData]], which I can't intercept access to).
(Though, Brendan says in his response that we probably shouldn't, and should instead just pledge to only add new methods onto Map subclasses. I don't think that's a particularly good idea, but it would address most of my problem.)
I agree that this is the preferred style of extensibility for both application developers and for libraries. Creating an enhance/specialized subclass avoids unintentional usage and conflict.
The even simpler course is to keep Map as spec'ed and make DOM or other specs work harder. Trade-offs...
The reason I'm really pushing on this is that it's not just DOM (we've already made the trade-off there, by adding [MapClass] to WebIDL), but user-space as well. I can't make a safe Counter class that's built on a Map unless I make the tradeoff above.
Did you mean [[MapData]]? [[MapData]] is just private state of the built-in object. If you're saving that you can't safely define certain abstractions with access to private state mechanism, then I agree you. But trying to turn [[MapData]] into an object level extension mechanism isn't the solution to your general problem.
No, I mean [MapClass]. dev.w3.org/2006/webapi/WebIDL/#MapClass It's a WebIDL extended attribute - the syntax has no relation to your use of [[foo]] in the ES spec. It declares the interface to be a Map subclass, setting Map.prototype on its prototype chain and providing default implementations of several Map methods for you. (This is especially helpful on the spec level, as you can then just define what the map entries are and then methods like get() are auto-defined for you.)
Other than the fact that WebIDL seems to continue to want to say "interface" when it really means "class", I don't have any problem with that. I suspect that in many cases it might be better to encapsulate rather than subclass map but in situations where the primary concept is that of a specialized Map, this seems fine.
On Aug 2, 2013, at 12:32 PM, Brendan Eich wrote:
Allen Wirfs-Brock wrote:
The iterator factory methods of map are all just short-cuts for creating "MapIterator" objects which are current specified as "friends" (in the C++ sense) that know about internal key/value store encapsulated by Map objects. The current spec. for MapInterator was written before we added 'forEach' to Map and arguably it could be re-specified in terms of 'foreach'.
This is a minor point, but internal iteration (forEach) and external (@@iterator) are not the same. How do you avoid rewriting to move the external consumer code into the forEach callback? Rewriting source is out.
However, that may take away some implementation level flexibility. Regardless, it's a possibility that I think I'll look into more deeply.
It's easier to layer internal iteration on external.
right, defining 'forEach' in terms of 'MapIterator' is the way to go.
Where we end up with is that the operations we would want for a Map-lite are get/set/delete/has/size/clear/forEach. They all need to know the implementation details of the underlying key/value store and for pragmatic reasons it doesn't make sense to try to reduce them to a smaller set of primitives.
That is exactly the interface of ES6 Map except that Map adds the trivial iterator factory method. It simply isn't worth having the added complexity of distinct Map and Map-lite classes simply to not have the iterator factory methods. For ES6 Map is Map-lite
We can debate whether future new methods should be added to Map or be made part of distinct new classes.
I think this is the underlying concern (Tab can confirm).
I'd suggest the latter for most cases. New methods are likely to incorporate domain concepts (eg, DOM stuff) that are not an essential part of the basic key/value store abstraction. It's better to define an appropriate domain specific abstraction that encapsulates a Map (or if you're an old school OO'er subclasses it) than it is to start adding new methods.
We should probably stack hands and even make this more than a suggestion. Between compatibility woes adding to Map.prototype later (see Array.prototype.values and @@unscopeable), and Tab's concern, I am ready to make it policy.
Me too,
On Fri, Aug 2, 2013 at 3:34 PM, Allen Wirfs-Brock <allen at wirfs-brock.com> wrote:
On Aug 2, 2013, at 12:32 PM, Brendan Eich wrote:
Allen Wirfs-Brock wrote:
We can debate whether future new methods should be added to Map or be made part of distinct new classes.
I think this is the underlying concern (Tab can confirm).
I'd suggest the latter for most cases. New methods are likely to incorporate domain concepts (eg, DOM stuff) that are not an essential part of the basic key/value store abstraction. It's better to define an appropriate domain specific abstraction that encapsulates a Map (or if you're an old school OO'er subclasses it) than it is to start adding new methods.
We should probably stack hands and even make this more than a suggestion. Between compatibility woes adding to Map.prototype later (see Array.prototype.values and @@unscopeable), and Tab's concern, I am ready to make it policy.
Me too,
I'm fine with this, but if this happens, I suggest reviewing Python's dict class and similar constructs in other languages to see if there's any other core operations we'll want to add to the main Map object before we freeze things.
For example, I think that Python's dict#update() isn't appropriate to push to a subclass.

Le 30/07/2013 00:12, Brendan Eich a écrit :
๏̯͡๏ Jasvir Nagra wrote:
Unless I am really misreading your examples, I do not think the new proposal overcomes the problems of harmony:typeof_null. If Function.setTypeOf dynamically affects subsequent use of typeof, then action-at-a-distance problems will persist. If one library adopts one convention regarding typeof null and another a different one, then these libraries will not be useable together.
Right, so don't do that
This is asking to never use any currently existing library. Fixing typeof null doesn't way enough and by a large factor.
There's no assumption of hostile code here, as usual you have to trust what you include into your single-frame/window (realm) TCB, etc. "This is a human-factors / phenomenology->likelihood problem."?
Le 30/07/2013 01:04, Brendan Eich a écrit :
Allen Wirfs-Brock wrote:
I would argue that Functioun.setTypeOf(null, "null") is actually a different kind of beast and one that you would want to be lexically scoped. The difference is that it is changing the meaning of a pre-existing operator applied to a pre-existing value. This reinterpretation really does need to be scoped only to code that wants to see that change.
Ok, good feedback between you and jasvir. This suggests using the syntax I mooted:
typeof null = "null"; // lexically rebind typeof null new code here typeof null = "object"; // restore for old code after
I'm not sure I understand how it's different from Function.setTypeOf. What happens if you don't restore? Does the rest of the program gets executed with typeof null === 'null'? If, for whatever reason, one doesn't restore, it seems that the semantics of code starts depending on execution order (thinking of script at async). Something I would avoid and recommend other devs to avoid. Also, all in all, I'd prefer Function.setTypeOf because it's deletable (like Object.prototype.proto)
Function.setTypeOf (or typeof null = 'whatever' assuming I understand the restore part right) is an ambiant capability that dynamically changes the whole-program semantics of typeof null. I hope I made the dynamic flavour of the feature sound scary enough for it to be considered as a bad idea :-)
I'm tempted to say "directive or nothing". But even as a directive, it's annoying as it makes code harder to read. In code, you'll almost never see: typeof x === "null" because x === null means the same thing and is shorter. The only cases in code where the directive would make a change is: typeof x === 'object' I imagine the mental burden to switch between some code using one behavior and some other code using another one will be big enough for people to think "fuck it! I'm going for the legacy behavior! That's the one people know and use anyway!"
If the things to think about when transitioning to strict mode [1] make a scale of annoying-ness, then typeof null would be placed in the worst category (semantic differences) and probably be the worst of these given that it's much more used than arguments, eval and this-in-non-OO-contexts (maybe combined). That makes transitionning code from old-typeof-null to new-typeof-null nothing be a nightmare.
I would love to see typeof null fixed or even fixable, but that probably takes a different language :-(
David

On Fri, Aug 2, 2013 at 3:02 PM, Allen Wirfs-Brock <allen at wirfs-brock.com>wrote:
On Aug 2, 2013, at 12:59 PM, Tab Atkins Jr. wrote:
On Fri, Aug 2, 2013 at 12:06 PM, Allen Wirfs-Brock ...
'size' is essentially a primitive of the key/value store.
It can be defined in terms of iterations, but I'm fine with this being primitive because it's such a small data leak. If you're subclassing Map such that the naive .size isn't what you want, you're doing something rather unusual.
More importantly, if you actually have a reason to taking the size of a Map (perhaps to preallocate an ArrayBuffer to hold a copy of the values) then you probably would like to avoid iteration size performance hit to compute the size value.
...
I'm less convinced of 'clear' - it's clearly a product of iteration + 'delete'. You're right that it's often more efficient to do directly, though.
Again it's pragmatics. If you have a reason for doing clears you probably want them to be fast.
As long as we're on this, I'd like to reiterate that we never achieved consensus on adding .clear() to WeakMap, so its inclusion in the draft spec is a bug. Further, as explained at < meetings:relationships.pdf>,
when we go through the use cases, it becomes clear that an implementation of WeakMap should always keep the associations on the key object, rather than in the WeakMap, so that the typical case collects garbage without needing to resort to the ephemeron collection algorithm. Adding .clear() to WeakMap makes this implementation strategy substantially more expensive.
Leveraging Tab's point, adding .clear() to WeakMap is not pragmatics. It fundamentally changes the nature of the abstraction.
David Bruant wrote:
Le 30/07/2013 00:12, Brendan Eich a écrit :
๏̯͡๏ Jasvir Nagra wrote:
Unless I am really misreading your examples, I do not think the new proposal overcomes the problems of harmony:typeof_null. If Function.setTypeOf dynamically affects subsequent use of typeof, then action-at-a-distance problems will persist. If one library adopts one convention regarding typeof null and another a different one, then these libraries will not be useable together.
Right, so don't do that This is asking to never use any currently existing library. Fixing typeof null doesn't way enough and by a large factor.
s/way/do/ ?
You could be right. We know lexical composes best, so I'm reworking the proto-strawman based on Jasvir's feedback.
There's no assumption of hostile code here, as usual you have to trust what you include into your single-frame/window (realm) TCB, etc. "This is a human-factors / phenomenology->likelihood problem."?
Sorry, you can't echo my words at me and win this argument. JS != SES. We do not assume mutual suspicion among same-origin and transcluded <script src=> scripts. Haven't for 17 years, won't start now.
Le 30/07/2013 01:04, Brendan Eich a écrit :
Allen Wirfs-Brock wrote:
I would argue that Functioun.setTypeOf(null, "null") is actually a different kind of beast and one that you would want to be lexically scoped. The difference is that it is changing the meaning of a pre-existing operator applied to a pre-existing value. This reinterpretation really does need to be scoped only to code that wants to see that change.
Ok, good feedback between you and jasvir. This suggests using the syntax I mooted:
typeof null = "null"; // lexically rebind typeof null new code here typeof null = "object"; // restore for old code after I'm not sure I understand how it's different from Function.setTypeOf.
The idea here is lexical scope, so the special forms compile to bindings that lexically alter typeof results, but library code scoped outside this extent is unaffected by these special forms.
Le 03/08/2013 02:59, Brendan Eich a écrit :
David Bruant wrote:
Le 30/07/2013 00:12, Brendan Eich a écrit :
๏̯͡๏ Jasvir Nagra wrote:
Unless I am really misreading your examples, I do not think the new proposal overcomes the problems of harmony:typeof_null. If Function.setTypeOf dynamically affects subsequent use of typeof, then action-at-a-distance problems will persist. If one library adopts one convention regarding typeof null and another a different one, then these libraries will not be useable together.
Right, so don't do that This is asking to never use any currently existing library. Fixing typeof null doesn't way enough and by a large factor.
s/way/do/ ?
s/way/weigh. I felt something was wrong with this sentence, but couldn't put the finger on it.
You could be right. We know lexical composes best, so I'm reworking the proto-strawman based on Jasvir's feedback.
for non-null too, I hope? Otherwise this is asking for non-compatible libraries for the built-in new value types
There's no assumption of hostile code here, as usual you have to trust what you include into your single-frame/window (realm) TCB, etc. "This is a human-factors / phenomenology->likelihood problem."?
Sorry, you can't echo my words at me and win this argument. JS != SES. We do not assume mutual suspicion among same-origin and transcluded <script src=> scripts. Haven't for 17 years, won't start now.
I understand now how I had misunderstood your words (in the context you put them and in this context where I mistakenly reused them). In any case, they applied only for the dynamic Function.setTypeOf.
Le 30/07/2013 01:04, Brendan Eich a écrit :
Allen Wirfs-Brock wrote:
I would argue that Functioun.setTypeOf(null, "null") is actually a different kind of beast and one that you would want to be lexically scoped. The difference is that it is changing the meaning of a pre-existing operator applied to a pre-existing value. This reinterpretation really does need to be scoped only to code that wants to see that change.
Ok, good feedback between you and jasvir. This suggests using the syntax I mooted:
typeof null = "null"; // lexically rebind typeof null new code here typeof null = "object"; // restore for old code after I'm not sure I understand how it's different from Function.setTypeOf.
The idea here is lexical scope, so the special forms compile to bindings that lexically alter typeof results, but library code scoped outside this extent is unaffected by these special forms.
oh ok. That makes much more sense now. Then the restore step is optional. I don't see the benefit of that against a file/function-wise directive.
For both null and the new value types, I'm still unclear on why could devs would choose something different than the default. I feel the incentives can only way in favor of keeping the default. I'm interested in what other devs think.
Le 03/08/2013 12:01, David Bruant a écrit :
For both null and the new value types, I'm still unclear on why could devs would choose something different than the default. I feel the incentives can only way
s/way/weigh/ I can't believe I just made the exact same mistake -_-#
David Bruant wrote:
Ok, good feedback between you and jasvir. This suggests using the syntax I mooted:
typeof null = "null"; // lexically rebind typeof null new code here typeof null = "object"; // restore for old code after I'm not sure I understand how it's different from Function.setTypeOf.
The idea here is lexical scope, so the special forms compile to bindings that lexically alter typeof results, but library code scoped outside this extent is unaffected by these special forms. oh ok. That makes much more sense now. Then the restore step is optional.
Yes, but the example would want a block then:
{ typeof null = "null"; new code here }
And yes, value objects would want a special form, but as I wrote,
typeof int64 = "int64";
is not symmetric with RHS typeof, so we'd want something else, not too chatty, maybe
typeof for int64 is "int64";
but as a special form, this requires evaluation of the expression int64, which must resolve to a value object factory function. And that (v.o.f.f.) needs to be defined first before noodling more with syntax.
I don't see the benefit of that against a file/function-wise directive.
Lexical means block in the modern Harmony era.
For both null and the new value types, I'm still unclear on why could devs would choose something different than the default. I feel the incentives can only [weigh] in favor of keeping the default. I'm interested in what other devs think.
I'm not sure what you mean re: "new value types". They have no "default" and "object" fails usability and useful-invariant requirements.
For null, are you sure people won't choose to "repair" this "ES regret" ? :
Le 03/08/2013 20:44, Brendan Eich a écrit :
David Bruant wrote:
I don't see the benefit of that against a file/function-wise directive.
Lexical means block in the modern Harmony era.
Excellent.
For both null and the new value types, I'm still unclear on why could devs would choose something different than the default. I feel the incentives can only [weigh] in favor of keeping the default. I'm interested in what other devs think.
I'm not sure what you mean re: "new value types". They have no "default" and "object" fails usability and useful-invariant requirements.
I need to re-read the proposal more in depth.
For null, are you sure people won't choose to "repair" this "ES regret" ? :-P
I'm doubtful for myself, but I'm really interested in what other devs think (but maybe we're too deep in thread nesting to have a big dev audience any longer :-p) This is quite a challenge to rewrite code to repair this regret. Maybe people have code that do (typeof x === typeof y) and expect null to come as an object. People coming from a Java background feel like typeof null === "object" is nothing but normal. The fact that Object.getPrototypeOf(Object.prototype) returns null also encourages this line of reasoning. I also recall that for one specific case [1] (oh! the indentation is awful!), I needed to play with the value returned by typeof (so doing more than just typeof x === y). That's very specific, but that would take time for me to transition to the repaired version of typeof with the same level of confidence. Just to save 20 chars, that doesn't sound like trouble I'd care to go into.
That said, I recently worked on a project and I reviewed a pull request with "typeof x === 'object'" to ask to replace to 'Object(x) === x'. I guess it would be nice if handling null didn't require encyclopedic knowledge of the language. But that's an opt-in and as of 2013, maybe 2014, I imagine that those who will know about how to fix typeof with the opt-in, will also know why it's there and how to avoid trouble in their own code.
Sorry for the hot and cold. Trying to share all relevant experience as a developer.
[1] (this line and 3 lines below) DavidBruant/ObjectViz/blob/ae4000925542f9393dc456be83566afa95bb35df/js/ObjectOwnViz.js#L92

Le 3 août 2013 à 12:01, David Bruant <bruant.d at gmail.com> a écrit :
For both null and the new value types, I'm still unclear on why could devs would choose something different than the default. I feel the incentives can only weigh in favor of keeping the default. I'm interested in what other devs think.
Having scanned my code, I can say that there is two cases where I regret to not have typeof null === "null":
(1) One situation is when I want to distinguish many cases and do a switch (typeof x). But for this case, most often, I'd like to "fix" not only typeof null, but also typeof array and typeof date...
(2) The other situation, more frequent, is when I want to distinguish a plain object from things like null or false. In this case typeof obj === 'object' has a false-positive, and I write either: typeof x === 'object' && x, or: typeof x === 'object' // assert: x !== null if the null value has been taken care before. It is really bad news that we risk to have typeof x === "object" by default when x is a value type, as it will invalidate my tests. Fixing typeof of old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunct Object.isObject(). (As a side-note, I suggest typeof uint64(0) === "number" rather than === "object" by default.)
But here is a potential good use of customisable typeof: I expect that sometimes you do not want to distinguish between int64, bignum, etc. (set typeof to "number" for all cases), but sometimes you do want to distinguish between them (set distinct typeof values). For this case, the scope of the modification should definitely be lexical, not dynamic.
On 8/3/2013 12:30 PM, David Bruant wrote:
That said, I recently worked on a project and I reviewed a pull request with "typeof x === 'object'" to ask to replace to 'Object(x) === x'.
I was actually the original author of that code. =D The function was:
function isObject(value){
let type = typeof value;
return type == "object" ? value !== null : type == "function";
}
Which would work just fine if typeof null was "null".
On a side note, I think your version of isObject is problematic because it requires allocating an object every time the function encounters a primitive. I'd prefer avoiding the unnecessary allocation in a function that is likely to be called very often.
Claude Pache wrote:
Fixing
typeofof old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunctObject.isObject(). (As a side-note, I suggesttypeof uint64(0) === "number"rather than=== "object"by default.)
That will make for bugs where number (double) loses precision, and other bugs where int64 carries too many bits of significand. It also violates the two-way
(typeof x == typeof y && x == y) <=> (x === y)
which we want for 0 == 0L, 1 == 1L, etc. (and consider other value types; this goes back to our work with Sam Ruby for IBM on decimal in 2008-9).
But here is a potential good use of customisable
typeof: I expect that sometimes you do not want to distinguish between int64, bignum, etc. (set typeof to "number" for all cases), but sometimes you do want to distinguish between them (set distinct typeof values). For this case, the scope of the modification should definitely be lexical, not dynamic.
We're not going to mix non-double numeric types -- types whose values do not project losslessly into IEEE-754 double -- as "number".
Brendan Eich wrote:
Claude Pache wrote:
Fixing
typeofof old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunctObject.isObject()
I forgot to add that my patch for bugzilla.mozilla.org/show_bug.cgi?id=749786 includes
Object.isObject(x) // false unless x is an object Object.isValue(x) // true for primitives and value objects
The idea: isObject returns true for all the new value object types and the reference-semantics objects found in JS today, while isValue returns true for all compare-by-value types, whether the legacy primitives (undefined, null, boolean, number, string) or the new-in-ES7 value objects.
Le 4 août 2013 à 01:39, Brendan Eich <brendan at mozilla.com> a écrit :
Brendan Eich wrote:
Claude Pache wrote:
Fixing
typeofof old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunctObject.isObject()I forgot to add that my patch for bugzilla.mozilla.org/show_bug.cgi?id=749786 includes
Object.isObject(x) // false unless x is an object Object.isValue(x) // true for primitives and value objects
The idea: isObject returns true for all the new value object types and the reference-semantics objects found in JS today, while isValue returns true for all compare-by-value types, whether the legacy primitives (undefined, null, boolean, number, string) or the new-in-ES7 value objects.
/be
Ok. What I am most interested, when I test for an "object", is roughly that I am able to get or set properties on it (ignoring restrictions or special cases like freezing, etc., and, in order to shorten the test, forgetting functions that are not supposed to occur). Or that it can be used like an object created by new Object (an Object-like). This probably coincides with !Object.isValue. Likely, I won't want to treat 1L like { } and differently from 1.
That numbers are non-objects but int64 are objects is much more an implementation detail than a relevant distinction for the programmer. So, I consider that typeof int64(0) === "object" and your Object.isObject are about as useless than typeof null === "object".
Le 4 août 2013 à 01:34, Brendan Eich <brendan at mozilla.com> a écrit :
Claude Pache wrote:
Fixing
typeofof old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunctObject.isObject(). (As a side-note, I suggesttypeof uint64(0) === "number"rather than=== "object"by default.)That will make for bugs where number (double) loses precision, and other bugs where int64 carries too many bits of significand. It also violates the two-way
(typeof x == typeof y && x == y) <=> (x === y)
which we want for 0 == 0L, 1 == 1L, etc. (and consider other value types; this goes back to our work with Sam Ruby for IBM on decimal in 2008-9).
So, if I understand well, this mandates that int64 and float32 (for example) should have different typeof values, ergo both "object" (as in [1]) and "number" (as I proposed) are equally bad answers, and the most reasonable default value of typeof for int64 would be "int64"?
Claude Pache wrote:
Le 4 août 2013 à 01:39, Brendan Eich<brendan at mozilla.com> a écrit :
Brendan Eich wrote:
Claude Pache wrote:
Fixing
typeofof old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunctObject.isObject()I forgot to add that my patch for bugzilla.mozilla.org/show_bug.cgi?id=749786 includesObject.isObject(x) // false unless x is an object Object.isValue(x) // true for primitives and value objects
The idea: isObject returns true for all the new value object types and the reference-semantics objects found in JS today, while isValue returns true for all compare-by-value types, whether the legacy primitives (undefined, null, boolean, number, string) or the new-in-ES7 value objects.
/be
Ok. What I am most interested, when I test for an "object", is roughly that I am able to get or set properties on it (ignoring restrictions or special cases like freezing, etc., and, in order to shorten the test, forgetting functions that are not supposed to occur).
Value objects are non-extensible, no-own-property (so effectively frozen), compare-by-value objects.
Or that it can be used like an object created by
new Object(an Object-like). This probably coincides with!Object.isValue. Likely, I won't want to treat1Llike{ }and differently from1.
Right, you want !Object.isValue(x).
That numbers are non-objects but int64 are objects is much more an implementation detail than a relevant distinction for the programmer.
Yes, that's intentional. I'm not sure we need the Object.is{Object,Value} APIs but they might be handy. Could go in the to-be-named Reflect module instead.
So, I consider that
typeof int64(0) === "object"and yourObject.isObjectare about as useless thantypeof null === "object".
You could be right -- if it's useless we should cut it. But it does provide a bit of information that's not the same as !Object.isValue, and which is a bit clumsy to piece together otherwise.
Claude Pache wrote:
Le 4 août 2013 à 01:34, Brendan Eich<brendan at mozilla.com> a écrit :
Claude Pache wrote:
Fixing
typeofof old (null) and new value types would be a solution, but I'm rather definitely considering something like the defunctObject.isObject(). (As a side-note, I suggesttypeof uint64(0) === "number"rather than=== "object"by default.) That will make for bugs where number (double) loses precision, and other bugs where int64 carries too many bits of significand. It also violates the two-way(typeof x == typeof y&& x == y)<=> (x === y)
which we want for 0 == 0L, 1 == 1L, etc. (and consider other value types; this goes back to our work with Sam Ruby for IBM on decimal in 2008-9).
So, if I understand well, this mandates that int64 and float32 (for example) should have different typeof values, ergo both "object" (as in [1]) and "number" (as I proposed) are equally bad answers, and the most reasonable default value of typeof for int64 would be "int64"?
Yes, this was the consensus at the meeting (not reflected in oksoclap.com/p/64ETm1ontG -- my fault -- but the slides are up to date and capture all the action items: www.slideshare.net/BrendanEich/value-objects).
That's out of date and I'm going to edit it for the next TC39 meeting. Thanks (to everyone who replied) for being a good sounding board here on es-discuss, in pre-strawman stage ;-).
On Aug 3, 2013, at 8:25 PM, Brendan Eich <brendan at mozilla.com> wrote:
Value objects are non-extensible, no-own-property (so effectively frozen), compare-by-value objects.
So, importantly, only one of the two existing commonly used tests for 'objectness' will continue to work correctly in the face of value objects. The first being a test that typeof is "object" or "function" that's not null, will continue to work. The second Object(value) === value would no longer work because a value object will return itself from Object.
On Aug 3, 2013, at 9:03 PM, Brandon Benvie <bbenvie at mozilla.com> wrote:
On Aug 3, 2013, at 8:25 PM, Brendan Eich <brendan at mozilla.com> wrote:
Value objects are non-extensible, no-own-property (so effectively frozen), compare-by-value objects.
So, importantly, only one of the two existing commonly used tests for 'objectness' will continue to work correctly in the face of value objects. The first being a test that typeof is "object" or "function" that's not null, will continue to work. The second
Object(value) === valuewould no longer work because a value object will return itself fromObject.
This brings up another question I hadn't thought of: the interaction between value objects and WeakMaps. A value object with an overridden strict equality comparison (is this on the table for builtin types?) can't be WeakMap keys probably.
Brandon Benvie wrote:
On Aug 3, 2013, at 8:25 PM, Brendan Eich<brendan at mozilla.com> wrote:
Value objects are non-extensible, no-own-property (so effectively frozen), compare-by-value objects.
So, importantly, only one of the two existing commonly used tests for 'objectness' will continue to work correctly in the face of value objects. The first being a test that typeof is "object" or "function" that's not null, will continue to work.
You must mean by 'objectness' reference-not-value semantics -- typeof returning "object" or "function" and the user ruling out null value (or opting into "null" result) doesn't do a thing to reject non-extensible, no-own-property objects of course.
The second
Object(value) === valuewould no longer work because a value object will return itself fromObject.
Yes, that's important. We don't want wrappers, they are the greater evil.
Brandon Benvie wrote:
On Aug 3, 2013, at 9:03 PM, Brandon Benvie<bbenvie at mozilla.com> wrote:
On Aug 3, 2013, at 8:25 PM, Brendan Eich<brendan at mozilla.com> wrote:
Value objects are non-extensible, no-own-property (so effectively frozen), compare-by-value objects. So, importantly, only one of the two existing commonly used tests for 'objectness' will continue to work correctly in the face of value objects. The first being a test that typeof is "object" or "function" that's not null, will continue to work. The second
Object(value) === valuewould no longer work because a value object will return itself fromObject.This brings up another question I hadn't thought of: the interaction between value objects and WeakMaps. A value object with an overridden strict equality comparison (is this on the table for builtin types?) can't be WeakMap keys probably.
s/probably/definitely/
This is covered already, see strawman:value_objects#weakmaps (note Object.isValue mention there).
Le 04/08/2013 00:10, Brandon Benvie a écrit :
On 8/3/2013 12:30 PM, David Bruant wrote:
That said, I recently worked on a project and I reviewed a pull request with "typeof x === 'object'" to ask to replace to 'Object(x) === x'.
On a side note, I think your version of isObject is problematic because it requires allocating an object every time the function encounters a primitive.
It's not required. That's the raw reading of the spec and that's probably what the implementations do, but it's not required. When reading "if(Object(x) === x)", the JS engine, at the time of calling "Object(x)" knows that the outcome won't be used except for its identity. It also knows that what matters isn't even the identity, but whether the identity is equal to x. In essence, the allocation isn't required per se.
I'd prefer avoiding the unnecessary allocation in a function that is likely to be called very often.
It's a very short-lived object anyway and Generational Garbage Collection is very efficient with them.
David Bruant wrote:
It's not required. That's the raw reading of the spec and that's probably what the implementations do, but it's not required. When reading "if(Object(x) === x)", the JS engine, at the time of calling "Object(x)" knows that the outcome won't be used except for its identity. It also knows that what matters isn't even the identity, but whether the identity is equal to x. In essence, the allocation isn't required per se.
Does any engine actually optimize away the wrapper?
It's a very short-lived object anyway and Generational Garbage Collection is very efficient with them.
TANSTAAFL.

From a dev standpoint what we need is a clean API to discriminate between types. Sometimes we want to discriminate between objects (mutable) and values (immutable), sometimes between functions and non functions, sometimes between numbers, strings and others, etc. And we don't want to have to write an extra test to exclude null from objects.
As we cannot break the existing typeof and its little warts, could we introduce a new call, something like Object.typeInfo(x), that would return a little hash like:
{ type: "int64", immutable: true, number: true, ... }
{ type: "string", immutable: true, number: false, ... }
{ type: "array", immutable: false, number, false, ... }
The idea it to have boolean flags like immutable/number/... to categorize types. This way we can discriminate by testing a flag instead of having to test complex combinations of typeof, Array.isArray, etc.
Le 05/08/2013 05:54, Brendan Eich a écrit :
Does any engine actually optimize away the wrapper?
Is this pattern used in a benchmark engines optimize against? Filed bugzilla.mozilla.org/show_bug.cgi?id=901442 on the SpiderMonkey side.

Would type annotations not be a cleaner way of achieving discrimination between types?
Would these APIs be redundant if we had type annotations?
David Bruant wrote:
Le 05/08/2013 05:54, Brendan Eich a écrit :
Does any engine actually optimize away the wrapper? Is this pattern used in a benchmark engines optimize against?
Not AFAIK, so I doubt any engine optimizes yet!
Le 4 août 2013 à 18:23, Brendan Eich <brendan at mozilla.com> a écrit :
You must mean by 'objectness' reference-not-value semantics -- typeof returning "object" or "function" and the user ruling out null value (or opting into "null" result) doesn't do a thing to reject non-extensible, no-own-property objects of course.
/be
There is a problem of terminology about what is called "object", and it will lead to confusions if not amended:
- For some technically reasonable definition of "object", Value Objects are objects.
- But for most programmers grown in a world where there is only Primitives and non-Value Objects (let's call them "Reference Objects"), Value Objects are better classified in the group of Primitives than in the group of Objects.
The reason is that Value Objects share the following features with Primitives, which constitute the practical important differences between them and Reference Objects:
- intrinsically immutable, with no own property;
- comparing by value.
The fact that Value Objects does not need wrapper in order to act like an object is an implementation detail that has almost no practical significance in the day-to-day life of the programmer (well, true, it will not break
instanceof...).
Incidentally, the fact that typeof evaluates to "object" for most Reference Objects but for almost no Primitives, reinforces the association of the word "object" to Reference Objects.
In this very thread, there have been at least three people in three days who have spontaneously called "object" things that are exclusively Reference Objects, although the very subject of this thread tells loudly that there is another kind of objects:
- myself: esdiscuss/2013-August/032545 (where
Object.isObject()ruled out Value Objects in my meaning); - Brandon Benvie: esdiscuss/2013-August/032553 (where "objectness" rules out Value Objects);
- Bruno Jouhier: esdiscuss/2013-August/032561 (where "objects (mutable)" is in contrast to "values (immutable)")
One radical solution is to revise the definition of "object", so that Value Objects are not objects. For example, what is currently called "object" would be named "thingummy", while the label "object" would roughly apply to intrinsically mutable, compare-by-reference thingummies.
Another less radical thing to do, is to de-emphasise the notion of "object" from the API, by excluding things like Object.isObject (programmers need rather !Object.isValue, anyway).
Bruno Jouhier wrote:
From a dev standpoint what we need is a clean API to discriminate between types. Sometimes we want to discriminate between objects (mutable) and values (immutable), sometimes between functions and non functions, sometimes between numbers, strings and others, etc. And we don't want to have to write an extra test to exclude null from objects.
As we cannot break the existing typeof and its little warts,
While we can't change typeof null without opt-in, there's good reason to believe we can extend the co-domain of typeof:
-
IE had non-standard results.
-
Extant code does not therefore not exhaustively enumerate result value cases.
-
Code does depend on the ==/=== invariant which motivates new typeof results for value objects (along with usability).
could we introduce a new call, something like Object.typeInfo(x), that would return a little hash like:
{ type: "int64", immutable: true, number: true, ... } { type: "string", immutable: true, number: false, ... } { type: "array", immutable: false, number, false, ... }
The first field is and should be what typeof returns.
What does "immutable" mean? We already have Object.isFrozen, etc., in ES5.
The "number" field is misleading in light of typeof 3.14 == "number".
The idea it to have boolean flags like immutable/number/... to categorize types. This way we can discriminate by testing a flag instead of having to test complex combinations of typeof, Array.isArray, etc.
Why would any code need to test combinations of those things to deal with value objects?
Array.isArray is irrelevant to value objects, but if you want typeof to return "array" for Array instances (how about subclasses of Array? How about array-likes?) that could be a separate opt-in. But those parenthetical questions need answers first.
There's no single typeof result that can tell all interesting facts about any value, especially composite values such as objects. OTOH there are good reasons to keep typeof working, and to minimize new APIs (as always) against use cases.
What are the use-cases -- let's say code examples from the field, or synthetic ones -- that you have in mind for your proposed API?
Brian Di Palma wrote:
Would type annotations not be a cleaner way of achieving discrimination between types?
The topic here was an introspective operator, typeof, or something similar.
Type annotations are a different category and even in static languages, do not relieve the need for introspection.
Also, type annotations to merit the name need a type system, and no one has found one that works for JS in full. Dart and TypeScript have "warning annotations" -- which also do not relieve the need for introspection a la typeof or instanceof.
Claude Pache wrote:
Le 4 août 2013 à 18:23, Brendan Eich<brendan at mozilla.com> a écrit :
You must mean by 'objectness' reference-not-value semantics -- typeof returning "object" or "function" and the user ruling out null value (or opting into "null" result) doesn't do a thing to reject non-extensible, no-own-property objects of course.
/be
There is a problem of terminology about what is called "object", and it will lead to confusions if not amended:
- For some technically reasonable definition of "object", Value Objects are objects.
- But for most programmers grown in a world where there is only Primitives and non-Value Objects (let's call them "Reference Objects"), Value Objects are better classified in the group of Primitives than in the group of Objects.
Yet without wrappers being typically observable or ever wanted. Just confirming here ;-).
I tend to take the "dessert topping and floor wax" approach. And indeed Object.isObject(0L) === Object.isValue(0L). Both!
The reason is that Value Objects share the following features with Primitives, which constitute the practical important differences between them and Reference Objects:
- intrinsically immutable, with no own property;
- comparing by value. The fact that Value Objects does not need wrapper in order to act like an object is an implementation detail that has almost no practical significance in the day-to-day life of the programmer (well, true, it will not break
instanceof...).
No more than instanceof is already broken, or cross-realm promiscuity is already broken (see "Realm, Schmealm!").
Incidentally, the fact that
typeofevaluates to "object" for most Reference Objects but for almost no Primitives, reinforces the association of the word "object" to Reference Objects.
Here there's a bigger difference users must attend do: not only null, but "function". The "function" result is not a matter of indifference or unwanted complexity as wrappers are -- it's JS's equivalent of Python's callable, we hope (it has not been, due to "host objects", but we're working to fix this).
In this very thread, there have been at least three people in three days who have spontaneously called "object" things that are exclusively Reference Objects, although the very subject of this thread tells loudly that there is another kind of objects:
- myself: esdiscuss/2013-August/032545 (where
Object.isObject()ruled out Value Objects in my meaning);- Brandon Benvie: esdiscuss/2013-August/032553 (where "objectness" rules out Value Objects);
- Bruno Jouhier: esdiscuss/2013-August/032561 (where "objects (mutable)" is in contrast to "values (immutable)")
Granted, but people are good at implicit learning and language adaptation. I'm not blowing it off, trying to put it in its proper place. But I'm game to explore alternatives too:
One radical solution is to revise the definition of "object", so that Value Objects are not objects. For example, what is currently called "object" would be named "thingummy", while the label "object" would roughly apply to intrinsically mutable, compare-by-reference thingummies.
Indeed in SpiderMonkey ages ago, I had an object < thing < value ontology reflected in naming conventions (object is-a gc-thing, string is-a gc-thing, both are values, boolean is-a value but not-a gc-thing, etc.).
Another less radical thing to do, is to de-emphasise the notion of "object" from the API, by excluding things like
Object.isObject(programmers need rather!Object.isValue, anyway).
I'm about ready to drop Object.isObject per your last message. But again it discloses something harder to discern otherwise.
How about Object.isReference?
Le 5 août 2013 à 19:14, Brendan Eich <brendan at mozilla.com> a écrit :
Claude Pache wrote:
Le 4 août 2013 à 18:23, Brendan Eich<brendan at mozilla.com> a écrit :
You must mean by 'objectness' reference-not-value semantics -- typeof returning "object" or "function" and the user ruling out null value (or opting into "null" result) doesn't do a thing to reject non-extensible, no-own-property objects of course.
/be
There is a problem of terminology about what is called "object", and it will lead to confusions if not amended:
- For some technically reasonable definition of "object", Value Objects are objects.
- But for most programmers grown in a world where there is only Primitives and non-Value Objects (let's call them "Reference Objects"), Value Objects are better classified in the group of Primitives than in the group of Objects.
Yet without wrappers being typically observable or ever wanted. Just confirming here ;-).
I tend to take the "dessert topping and floor wax" approach. And indeed Object.isObject(0L) === Object.isValue(0L). Both!
The reason is that Value Objects share the following features with Primitives, which constitute the practical important differences between them and Reference Objects:
- intrinsically immutable, with no own property;
- comparing by value. The fact that Value Objects does not need wrapper in order to act like an object is an implementation detail that has almost no practical significance in the day-to-day life of the programmer (well, true, it will not break
instanceof...).No more than instanceof is already broken, or cross-realm promiscuity is already broken (see "Realm, Schmealm!").
Incidentally, the fact that
typeofevaluates to "object" for most Reference Objects but for almost no Primitives, reinforces the association of the word "object" to Reference Objects.Here there's a bigger difference users must attend do: not only null, but "function". The "function" result is not a matter of indifference or unwanted complexity as wrappers are -- it's JS's equivalent of Python's callable, we hope (it has not been, due to "host objects", but we're working to fix this).
In this very thread, there have been at least three people in three days who have spontaneously called "object" things that are exclusively Reference Objects, although the very subject of this thread tells loudly that there is another kind of objects:
- myself: esdiscuss/2013-August/032545 (where
Object.isObject()ruled out Value Objects in my meaning);- Brandon Benvie: esdiscuss/2013-August/032553 (where "objectness" rules out Value Objects);
- Bruno Jouhier: esdiscuss/2013-August/032561 (where "objects (mutable)" is in contrast to "values (immutable)")
Granted, but people are good at implicit learning and language adaptation. I'm not blowing it off, trying to put it in its proper place. But I'm game to explore alternatives too:
One radical solution is to revise the definition of "object", so that Value Objects are not objects. For example, what is currently called "object" would be named "thingummy", while the label "object" would roughly apply to intrinsically mutable, compare-by-reference thingummies.
Indeed in SpiderMonkey ages ago, I had an object < thing < value ontology reflected in naming conventions (object is-a gc-thing, string is-a gc-thing, both are values, boolean is-a value but not-a gc-thing, etc.).
Another less radical thing to do, is to de-emphasise the notion of "object" from the API, by excluding things like
Object.isObject(programmers need rather!Object.isValue, anyway).I'm about ready to drop Object.isObject per your last message. But again it discloses something harder to discern otherwise.
I'm confident that anyone sufficiently nerd to want to take advantage of the difference between primitives and value objects, will know how to do it without our aid. :-)
You're right that people are good at language adaptation, thus it is not necessary to go as far as to change the nomenclature. The main concern remains, that they use today Object.isObject by meaning probably isReferenceObject, so it is prudent not to standardise something else under this very name.
How about Object.isReference?
Instead of !Object.isValue? Indeed, for me I test more naturally for a Reference Object ("is it an Object-like or not?") than for a Value. Plus, s/ \b Object.isObject \b / Object.isReference /xg would refactor some expected legacy code in an twinkling of an eye.
Claude Pache wrote:
You're right that people are good at language adaptation, thus it is not necessary to go as far as to change the nomenclature. The main concern remains, that they usetoday
Object.isObjectby meaning probablyisReferenceObject, so it is prudent not to standardise something else under this very name.
Agreed -- I will fix in the forthcoming strawman revision.
How about Object.isReference?
Instead of
!Object.isValue?
Yes, in case that is a sharper way to phrase it.
Indeed, for me I test more naturally for a Reference Object ("is it an Object-like or not?") than for a Value. Plus,
s/ \b Object.isObject \b / Object.isReference /xgwould refactor some expected legacy code in an twinkling of an eye.
Great point. Sold. Thanks for the patient and thoughtful feedback!
See www.slideshare.net/BrendanEich/value-objects (tweet: twitter.com/BrendanEich/status/360538755309912064), in particular slide 13:
typeof travails and travesties
typeof x == typeof y && x == yx === y0m == 0 && 0L == 0means0m == 0L(transitivity), but0m !== 0L(different precision and radix) sotypeof 0m != typeof 0Lper the invarianttypeof 0L == "int64"andtypeof 0m == "decimal"anywaytypeofextensible requires a per-realm registry with throw-on-conflictThe appendix of this post proposes how to make typeof extensible, with throw-on-conflict in general. A special case for null allows
Function.setTypeOf(null, "null")and
Function.setTypeOf(null, "object")to be called multiple times per realm, so new code can opt into sane typeof null. The attempt to break compatibility for ES6 proposed at harmony:typeof_null failed by being too web-incompatible, but given
Function.setTypeOffor value objects, it's easy to support opt-in typeof repair.I considered syntax instead of API:
typeof null = "null";(i.e., heretofore illegal left-hand side expressions consisting of typeof unary expressions), but this fails to express the symmetric relationship when applied to value object constructors:
typeof bignum = "bignum";does not match runtime sense of
(typeof bignum), which must return"function". Instead,Function.setTypeOf(bignum, "bignum")works with minimal boilerplate (the
.prototypeis implicit for the first parameter) and the value-object-constructor-function-or-null leading parameter fits the Function-static namespacing.As promised, other than when passing null as the first actual parameter,
Function.setTypeOfthrows on conflict.Comments welcome.
extensible typeof proposal
Per-real typeof customization API, for two use-cases:
Two Map instances, internal to the specification:
New
Function.setTypeOfstatic, a peer ofFunction.defineOperator:Function.setTypeOf(V, U)From the draft ES6 spec:
Notes: